Let’s consider a sequence of random variables \(\mathbf{X}_n = (X_1,\dots,X_n)\) with known parametric joint density defined by a vector of parameters \(\boldsymbol{\theta}_0\) with dimension \(p\). Then, \(f\) can be seen as a function that takes as input a vector in \(\mathbb{R}^{n + p}\) and gives as output a scalar in \(\mathbb{R}^{+}\). In fact, \(n\) arguments come from a possible realized sample \(\mathbf{x}_n = (x_1,\dots,x_n)\), while \(p\) arguments come from the vector of parameters \(\boldsymbol{\theta} = (\theta_1,\dots,\theta_p) \in \Theta\), where \(\Theta\) is an admissible parameter space, i.e. \[
f_{X_1,\dots,X_n; \theta_1, \dots, \theta_p}: \mathbb{R}^n \times \mathbb{R}^p \to \mathbb{R}^{+}
\] In general, when the set of parameters \(\boldsymbol{\theta}\) is considered fixed and the input of the function is only a vector of random variables or scalar in \(\mathbb{R}^n\), then \(f\) is called density function, i.e. \[
f_{\mathbf{X}_n}(\mathbf{X}_n \mid \boldsymbol{\theta}):
\mathbb{R}^{n}
\to
\mathbb{R}^{+}
\text{,}
\] On the other hand, when we fix a sample \(\mathbf{X}_n = \mathbf{x}_n\) to a particular value and let the vector of parameters be the input of the function, one obtains the observed likelihood, i.e. \[
f_{\mathbf{X}_n}(\boldsymbol{\theta} \mid \mathbf{X}_n = \mathbf{x}_n):
\mathbb{R}^{p}
\to
\mathbb{R}^{+}
\text{,}
\] that represents the probability of observing the realized sample (\(\mathbf{X}_n = (x_1,\dots,x_n)\)), given a vector of parameters \(\boldsymbol{\theta}\). Usually, the likelihood is denoted as \[
\mathcal{L}(\boldsymbol{\theta} \mid \mathbf{X}_n = \mathbf{x}_n) = \mathcal{L}(\boldsymbol{\theta}\mid x_1,\dots,x_n)
\text{.}
\tag{11.1}\] In practice, for a given value of \(\boldsymbol{\theta}\), the likelihood expresses how likely it is that the data are generated under the distributive law implied by \(f_{X_1, \dots, X_n}\). The observed log-likelihood function \(\ell\) is computed by taking the logarithm of the likelihood (Equation 11.1), i.e. \[
\ell(\boldsymbol{\theta}\mid \mathbf{X}_n = \mathbf{x}_n)
= \log(\mathcal{L}(\boldsymbol{\theta}\mid \mathbf{X}_n = \mathbf{x}_n))
\text{.}
\tag{11.2}\] When the log-likelihood is differentiable, we can define the observed gradient (Equation 31.9) of the log-likelihood with respect to the parameter’s vector \(\boldsymbol{\theta}\) and computed on a realized sample \(\mathbf{x}_n\), i.e. \[
\nabla_{\ell}(\boldsymbol{\theta} \mid \mathbf{x}_n) =
\begin{pmatrix}
\frac{\partial \ell}{\partial \theta_1}(\boldsymbol{\theta} \mid \mathbf{x}_n) \\
\frac{\partial \ell}{\partial \theta_2}(\boldsymbol{\theta} \mid \mathbf{x}_n) \\
\vdots \\
\frac{\partial \ell}{\partial \theta_p}(\boldsymbol{\theta} \mid \mathbf{x}_n)
\end{pmatrix}
\] and the observed Jacobian (Equation 31.10) of the gradient, i.e. \[
\mathbf{J}_{\ell}(\boldsymbol{\theta}\mid \mathbf{x}_n) =
\begin{pmatrix}
\partial^2_{\theta_1} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n) &
\partial_{\theta_1}\partial_{ \theta_2} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n)
& \dots &
\partial_{\theta_1}\partial_{\theta_p} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n) \\
\partial_{\theta_2} \partial_{\theta_1} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n) &
\partial^2_{\theta_2} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n)
& \dots &
\partial_{\theta_2}\partial_{\theta_p} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n) \\
\vdots & \vdots & \ddots & \vdots \\
\partial_{\theta_p} \partial_{\theta_1} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n) &
\partial_{\theta_p} \partial_{\theta_2} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n)
& \dots &
\partial^2_{\theta_p} \ell(\boldsymbol{\theta} \mid \mathbf{x}_n)
\end{pmatrix}
\text{,}
\] If we consider the gradient as function of the random variables, then the population Score is the expected value of the gradient, i.e. \[
S(\boldsymbol{\theta}) =
\mathbb{E}\{\nabla_{\ell}(\boldsymbol{\theta} \mid \mathbf{X}_n)\}
\text{,}
\tag{11.3}\] Notably, when the joint density function is correctly specified, the Score computed at the true population parameter \(\boldsymbol{\theta}_0\) is equal to zero, i.e. \[
S(\boldsymbol{\theta}_0) = 0
\text{.}
\] Similarly, we define the population Hessian the matrix defined as the expected value of the Jacobian of the Score, i.e. \[
\mathcal{H}(\boldsymbol{\theta}) = \mathbb{E}\{\mathbf{J}_{\ell}(\boldsymbol{\theta} \mid \mathbf{X}_n)\}
\tag{11.4}\] Notably, the following relation \[
\mathbb{E}\{\mathbf{J}_{\ell}(\boldsymbol{\theta} \mid \mathbf{X}_n)\} =
\mathbb{E}\{\nabla_{\ell} (\boldsymbol{\theta} \mid \mathbf{X}_n) \nabla^{\top}_{\ell} (\boldsymbol{\theta} \mid \mathbf{X}_n)\}
\] holds only if the model is correctly specified; otherwise, under misspecification, it does not hold anymore. The Fisher information is related to the population Hessian matrix as follows \[
\mathcal{I}(\boldsymbol{\theta}) = -\mathcal{H}(\boldsymbol{\theta})
\text{.}
\tag{11.5}\]
11.1 ML Estimator
In statistics, a method of estimating the unknown true vector of parameters \(\boldsymbol{\theta}_0\) is the Maximum Likelihood (ML).
Under the assumption that the observed sample comes from a known parametric density function \(f_{\mathbf{X}_n}\), the maximum likelihood estimators are obtained by maximizing a likelihood function so that, under the assumed distributive law, the observed data are the most probable.
More precisely considering a realized sample, namely \(\mathbf{X}_n = \mathbf{x}_n\) where \(\mathbf{x}_n = (x_1, \dots, x_n)\), then the Maximum Likelihood Estimator (MLE) denoted as \(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}\), maximizes the likelihood (Equation 11.1), i.e. \[
\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n =
\underset{\boldsymbol{\theta} \in \Theta}{\arg \max}
\left[\mathcal{L}(\boldsymbol{\theta} \mid \mathbf{x}_n)\right]
\text{.}
\] Since the logarithm is a monotone function, instead of maximizing directly the likelihood, usually it is preferable to maximize the log-likelihood (Equation 11.2) or minimize the negative log-likelihood, i.e. \[
\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n = \underset{\boldsymbol{\theta} \in \Theta}{\arg \max} \left[\ell(\boldsymbol{\theta} \mid \mathbf{x}_n)\right]
\iff
\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n = \underset{\boldsymbol{\theta} \in \Theta}{\arg \min} \left[-\ell(\boldsymbol{\theta} \mid \mathbf{x}_n)\right]
\text{.}
\] In general, the true population score (Equation 11.3) is not directly observable, therefore given a realized sample \(\mathbf{x}_n\), the maximum likelihood estimator solves the system of observed Score equations equal to zero. More precisely, in the vector case the first order conditions (FOC) for the occurrence of a maximum (or a minimum) are \[
\nabla_{\ell}(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n) = 0
\iff
\begin{cases}
\partial_{\theta_1} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) = 0 \\
\partial_{\theta_2} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) = 0 \\
\quad \vdots \\
\partial_{\theta_p} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) = 0
\end{cases}
\tag{11.6}\] In general, these equations may not have a closed-form solution, so the estimate is obtained by numerical methods.
The observed Jacobian is the matrix of second-order partial and cross-partial derivatives computed at the MLE estimate \[
\mathbf{J}_{\ell}(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) =
\begin{pmatrix}
\partial^2_{\theta_1} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) &
\partial_{\theta_1}\partial_{ \theta_2} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n)
& \dots &
\partial_{\theta_1}\partial_{\theta_p} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) \\
\partial_{\theta_2} \partial_{\theta_1} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) &
\partial^2_{\theta_2} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n)
& \dots &
\partial_{\theta_2}\partial_{\theta_p} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) \\
\vdots & \vdots & \ddots & \vdots \\
\partial_{\theta_p} \partial_{\theta_1} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n) &
\partial_{\theta_p} \partial_{\theta_2} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n)
& \dots &
\partial^2_{\theta_p} \ell(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n \mid \mathbf{x}_n)
\end{pmatrix}
\text{,}
\] and represents the actual curvature of the log-likelihood at the observed sample. To ensure a strict local maximum the observed Jacobian must be negative-definite when computed at the MLE estimate, i.e. when \(\boldsymbol{\theta} = \hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n\).
Global vs. local maximum
In general, if the Hessian is positive-definite (all eigenvalues positive) at \(\boldsymbol{\theta}^{\tiny \text{ML}}\), then it corresponds to a local minimum. If the Hessian is negative-definite (all eigenvalues negative), then it corresponds to a local maximum. If the Hessian has both positive and negative eigenvalues, then it corresponds to a saddle point (not a maximum, not a minimum).
If the entire log-likelihood function \(\ell\) is globally concave in \(\theta\) (i.e. \(\mathbf{J}_{\ell}(\theta)\) is negative semi-definite everywhere), then any local maximum is automatically a global maximum. But if \(\ell\) is not globally concave, the negative definiteness at \(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}\) only guarantees a local maximum. Many classical families of distributions have log-concave likelihoods, for example Exponential family distributions (Normal with known variance, Poisson, Bernoulli, Exponential, etc.) have log-likelihoods that are globally concave in their natural parameters. In those cases, the negative definiteness at a stationary point implies that this stationary point is the unique global maximizer. On the other hand, for example Mixture models (e.g. Gaussian mixtures) have non-concave likelihoods and may admit multiple local maxima. The MLE can then be non-unique and may converge to a local maximum.
Invariance property MLE
A property of MLE is the invariance under monotone transformations, i.e. if \(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n\) is the MLE of \(\boldsymbol{\theta}\), then for any one-to-one transformation \(\boldsymbol{\phi}=g(\boldsymbol{\theta})\), the MLE of \(\boldsymbol{\phi}\) is \(\hat{\boldsymbol{\phi}}^{\tiny \text{ML}} = g(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n)\).
11.1.1 Independent sample
In the special case in which the sample is composed of independent observations, the joint density factorizes into the product of the single densities, i.e. \[
f_{\mathbf{X}_n}(x_1, \dots, x_i, \dots x_n \mid \boldsymbol{\theta}) = \prod_{i=1}^n f_{X_i}(x_i\mid \boldsymbol{\theta})
\text{.}
\] Therefore, also the log-likelihood (Equation 11.1) simplifies into the sum of the log-likelihoods where \(f_{X_i}\) can be different for each random variable \(X_i\), i.e. \[
\ell(\boldsymbol{\theta}\mid \mathbf{x}_n)
= \sum_{i=1}^n \ell_{i}(\boldsymbol{\theta}\mid x_i)
\text{,}
\] where the log-likelihood given the \(x_i\) observation depends on the density of \(X_i\) and reads \[
\ell_i(\boldsymbol{\theta} \mid x_i) = \log \left[f_{X_i}(x_i\mid \boldsymbol{\theta})\right]
\text{.}
\] and the true population Score reads \[
S_i(\boldsymbol{\theta}) =
\mathbb{E}\{\nabla_{\ell_i}(\boldsymbol{\theta} \mid X_i)\}
\text{.}
\] Hence, the total gradient vector is obtained as the sum of the gradients per observation, i.e. \[
\nabla_{\ell} (\boldsymbol{\theta}) =
\sum_{i=1}^n \nabla_{\ell_i}(\boldsymbol{\theta} \mid x_i)
=
\begin{pmatrix}
\sum_{i=1}^n\frac{\partial \ell_{i}(\boldsymbol{\theta}\mid x_i)}{\partial \theta_1} \\
\sum_{i=1}^n\frac{\partial \ell_{i}(\boldsymbol{\theta}\mid x_i)}{\partial \theta_2} \\
\vdots \\
\sum_{i=1}^n\frac{\partial \ell_{i}(\boldsymbol{\theta}\mid x_i)}{\partial \theta_p}
\end{pmatrix}
\text{.}
\] and the true population Score is the sum of the scores per observations, i.e. \[
S(\boldsymbol{\theta}) = \sum_{i = 1}^{n} S_i(\boldsymbol{\theta})
\text{,}
\] Similarly, the Jacobian of the \(i\)-th observation reads \[
\mathbf{J}_{\ell_i}(\boldsymbol{\theta} \mid x_i) =
\begin{pmatrix}
\partial^2_{\theta_1} \ell_i(\boldsymbol{\theta} \mid x_i) &
\partial_{\theta_1}\partial_{ \theta_2} \ell_i(\boldsymbol{\theta} \mid x_i)
& \dots &
\partial_{\theta_1}\partial_{\theta_p} \ell_i(\boldsymbol{\theta} \mid x_i) \\
\partial_{\theta_2} \partial_{\theta_1} \ell_i(\boldsymbol{\theta} \mid x_i) &
\partial^2_{\theta_2} \ell_i(\boldsymbol{\theta} \mid x_i)
& \dots &
\partial_{\theta_2}\partial_{\theta_p} \ell_i(\boldsymbol{\theta} \mid x_i) \\
\vdots & \vdots & \ddots & \vdots \\
\partial_{\theta_p} \partial_{\theta_1} \ell_i(\boldsymbol{\theta} \mid x_i) &
\partial_{\theta_p} \partial_{\theta_2} \ell_i(\boldsymbol{\theta} \mid x_i)
& \dots &
\partial^2_{\theta_p} \ell_i(\boldsymbol{\theta} \mid x_i)
\end{pmatrix}
\text{,}
\] For independent samples, the Hessian per observation \[
\mathcal{H}_{i}(\boldsymbol{\theta}) = \mathbb{E}\{\mathbf{J}_{\ell_i}(\boldsymbol{\theta} \mid X_i)\}
\text{.}
\] and the Fisher information per observation \[
\mathcal{I}_{i}(\boldsymbol{\theta}) = -\mathcal{H}_{i}(\boldsymbol{\theta})
\text{.}
\] Therefore, the total Hessian in population reads \[
\mathcal{H}(\boldsymbol{\theta}) = \sum_{i=1}^n \mathcal{H}_{i}(\boldsymbol{\theta})
\text{.}
\] and the total Fisher information \[
\mathcal{I}(\boldsymbol{\theta}) = \sum_{i=1}^n \mathcal{I}_{i}(\boldsymbol{\theta})
\text{.}
\]
11.1.2 IID sample
In the special case in which the sample is composed of independent and identically distributed observations, the joint density factorizes as \[
f_{\mathbf{X}_n}(x_1, \dots, x_i, \dots x_n \mid \boldsymbol{\theta}) = \prod_{i=1}^n f_{X_1}(x_i\mid \boldsymbol{\theta})
\text{.}
\] Therefore, also the log-likelihood (Equation 11.1) simplifies \[
\ell(\boldsymbol{\theta}\mid \mathbf{x}_n) = \sum_{i=1}^n \ell(\boldsymbol{\theta}\mid x_i)
\text{.}
\] where \[
\ell(\boldsymbol{\theta}\mid x_i) = \log \left[f_{X_1}(x_i \mid \boldsymbol{\theta})\right]
\text{.}
\] In this case, the gradient of the log-likelihood depends only on the different values assumed by \(x_i\), i.e. \[
\nabla_{\ell}(\boldsymbol{\theta} \mid x_i) =
\begin{pmatrix}
\frac{\partial \ell(\boldsymbol{\theta}\mid x_i)}{\partial \theta_1} \\
\frac{\partial \ell(\boldsymbol{\theta}\mid x_i)}{\partial \theta_2} \\
\vdots \\
\frac{\partial \ell(\boldsymbol{\theta}\mid x_i)}{\partial \theta_p}
\end{pmatrix}
\text{,}
\] and the total gradient reads \[
\nabla_{\ell}(\boldsymbol{\theta} \mid \mathbf{x}_n) =
\sum_{i=1}^n \nabla_{\ell}(\boldsymbol{\theta} \mid x_i)
\text{,}
\] Therefore, taking the expected value of the gradient one recover the population score (Equation 11.3), i.e. \[
S(\boldsymbol{\theta}) = n \mathbb{E}\{\nabla_{\ell}(\boldsymbol{\theta} \mid X_1)\}
\text{.}
\] Similarly, the matrix with the second derivatives \[
\mathbf{J}_{\ell}(\boldsymbol{\theta} \mid x_i) =
\begin{pmatrix}
\partial^2_{\theta_1} \ell(\boldsymbol{\theta} \mid x_i) &
\partial_{\theta_1}\partial_{ \theta_2} \ell(\boldsymbol{\theta} \mid x_i)
& \dots &
\partial_{\theta_1}\partial_{\theta_p} \ell(\boldsymbol{\theta} \mid x_i) \\
\partial_{\theta_2} \partial_{\theta_1} \ell(\boldsymbol{\theta} \mid x_i) &
\partial^2_{\theta_2} \ell(\boldsymbol{\theta} \mid x_i)
& \dots &
\partial_{\theta_2}\partial_{\theta_p} \ell(\boldsymbol{\theta} \mid x_i) \\
\vdots & \vdots & \ddots & \vdots \\
\partial_{\theta_p} \partial_{\theta_1} \ell(\boldsymbol{\theta} \mid x_i) &
\partial_{\theta_p} \partial_{\theta_2} \ell(\boldsymbol{\theta} \mid x_i)
& \dots &
\partial^2_{\theta_p} \ell(\boldsymbol{\theta} \mid x_i)
\end{pmatrix}
\text{,}
\] Hence, Hessian per observation is the same for each \(X_i\), i.e. \[
\mathcal{H}_i(\boldsymbol{\theta}) = \mathbb{E}\{\mathbf{J}_{\ell}(\boldsymbol{\theta} \mid X_1)\}
\text{.}
\] and the Fisher information per observation \[
\mathcal{I}_{i}(\boldsymbol{\theta}) = -\mathbb{E}\{\mathbf{J}_{\ell}(\boldsymbol{\theta} \mid X_1)\}
\text{.}
\] Therefore the total Hessian in population is \[
\mathcal{H}(\boldsymbol{\theta}) = n \mathbb{E}\{\mathbf{J}_{\ell}(\boldsymbol{\theta} \mid X_1)\}
\text{.}
\] and the total Fisher Information \[
\mathcal{I}(\boldsymbol{\theta}) = n \mathbb{E}\{\mathbf{J}_{\ell}(\boldsymbol{\theta} \mid X_1)\}
\text{.}
\]
Exercise 11.1 Let’s consider an IID sample \(\mathbf{x}_n = (x_1, \dots, x_n)\), where each \(x_i\) is drawn from a normal distribution \(X_i \sim \mathcal{N}(\mu, \sigma^2)\) with known variance \(\sigma^2\). The likelihood, given a realized sample and the known variance reads \[
\mathcal{L}_{\mathbf{X}_n}(\mu \mid \mathbf{x}_n, \sigma^2) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x_i - \mu)^2}{2\sigma^2}\right)
\text{.}
\tag{11.7}\] Compute the Fisher information according to Equation 11.5.
Solution 11.1. Let’s consider the given joint density, then by definition (Equation 11.2) the log-likelihood function of the \(x_i\) observation, given \(\sigma^2\) reads: \[
\ell(\mu \mid x_i, \sigma^2)
=
- \frac{1}{2}\log(2\pi)
- \frac{1}{2}
\left[
\log(\sigma^2) \left(\frac{x_i - \mu}{\sigma}\right)^2
\right]
\text{.}
\] Therefore, the total log-likelihood is the sum of the log-likelihoods \[
\ell(\mu \mid x_i, \sigma^2) =
\sum_{i=1}^n
\ell(\mu \mid x_i, \sigma^2) =
- \frac{n}{2} \log(2\pi)
- \frac{n}{2} \log(\sigma^2)
- \frac{1}{2 \sigma^2} \sum_{i=1}^n\left(x_i - \mu\right)^2
\text{.}
\] The first derivative of the log-likelihood (Equation 11.3) with respect to the mean parameter \(\mu\) given the observation \(x_i\) reads \[
\frac{\partial \ell(\mu \mid x_i, \sigma^2)}{\partial \mu}
= \frac{x_i - \mu}{\sigma^2}
\text{.}
\] and the second derivative \[
\frac{\partial^2 \ell(\mu \mid x_i, \sigma^2)}{\partial \mu^2}
= -\frac{1}{\sigma^2}
\text{.}
\] Therefore, the Score with respect to \(\mu\) is the sum of the scores, i.e. \[
\frac{\partial \ell(\mu \mid \mathbf{x}_n, \sigma^2)}{\partial \mu}
= \frac{1}{\sigma^2}\sum_{i=1}^n (x_i - \mu)
\text{,}
\] and similarly \[
\frac{\partial^2 \ell(\mu \mid \mathbf{x}_n, \sigma^2)}{\partial \mu^2}
= -\frac{n}{\sigma^2}
\text{,}
\] Hence, the Fisher information (Equation 11.5) reads \[
\begin{aligned}
\mathcal{I}(\mu) & {} = - n \mathbb{E}\left\{\frac{\partial^2 \ell(\mu \mid \sigma^2, X_1)}{\partial \mu^2} \right\} = \frac{n}{\sigma^2} \text{.}
\end{aligned}
\] Intuitively, since for a Normal random variable a greater \(\sigma^2\) implies a more dispersed distribution with respect to the center (\(\mu\)), the Information related to the mean parameter contained in an observed sample with \(n\) observations decreases when \(\sigma^2\) increases. Moreover, it is interesting to note that as the number of observations increases (\(n \to \infty\)), the impact of any variance parameter \(0 < \sigma^2 < \infty\) becomes negligible.
11.1.3 Properties MLE
Let \(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n\) be the MLE estimate of some unknown true population parameter \(\boldsymbol{\theta}_0\). Then, under the main regularity conditions (i.e. identifiability, differentiability, non-singularity of the Fisher Information), the MLE estimator has two fundamental properties:
Consistency: the MLE is consistent for the true population parameter \(\boldsymbol{\theta}_0\) in the sense that, as the number of observations \(n\) increases it converges in probability to the true population parameter, i.e. \[
\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n
\overset{\text{p}}{\underset{n \to \infty}{\longrightarrow}}
\boldsymbol{\theta}_0
\text{.}
\]
Asymptotic Normality: The asymptotic joint distribution of the MLE estimate is Multivariate Normal with dimension \(p\), where \(p\) is the number of parameters, i.e. \[
\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n
\overset{\text{d}}{\underset{n \to \infty}{\longrightarrow}}
\text{MVN}_p \left(\boldsymbol{\theta}_0, \frac{1}{n} \mathcal{I}^{-1}(\boldsymbol{\theta})
\right)
\text{,}
\] equivalently, the distribution of the rescaled estimation error converges to a multivariate normal with mean zero and covariance matrix given by the inverse Fisher information, i.e. \[
\sqrt{n}(\hat{\boldsymbol{\theta}}^{\tiny \text{ML}}_n - \boldsymbol{\theta}_0)
\overset{\text{d}}{\underset{n \to \infty}{\longrightarrow}}
\text{MVN}_p \left(\mathbf{0}, \mathcal{I}^{-1}(\boldsymbol{\theta})\right)
\text{.}
\]
11.1.4 MLE in the Gaussian case
Let’s consider a sample of \(n\) independent and identically distributed random variables \(\mathbf{x}_n = \{x_1, x_2, \ldots, x_n\}\). All the observation are extracted from the same probability distribution that is Normal with unknown true population’s parameters \(\mu\) and \(\sigma^2\). In specific, the joint density of \(n\) IID Normal random variables reads as in Equation 11.7. Thus, the likelihood is a function of the unknown parameters given the observed data, i.e. \[
\mathcal{L}(\mu, \sigma^2 \mid \mathbf{x}_n) = \prod_{i=1}^n \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{(x_i - \mu)^2}{2 \sigma^2}\right)
\text{.}
\] The log-likelihood function (Equation 11.2) is obtained by taking the natural logarithm of the likelihood, i.e. \[
\begin{aligned}
\ell(\mu, \sigma^2 \mid X_n) & {} = \ln \mathcal{L}(\mu, \sigma^2 \mid X_n) = \\
& = \sum_{i=1}^n \ln \left( \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{(x_i - \mu)^2}{2 \sigma^2}\right) \right) = \\
& = \sum_{i=1}^n \left( -\frac{1}{2} \ln (2 \pi) -\frac{1}{2} \log (\sigma^2) - \frac{(x_i - \mu)^2}{2 \sigma^2} \right) = \\
& = -\frac{n}{2} \ln (2 \pi) -\frac{n}{2} \ln (\sigma^2) - \frac{1}{2 \sigma^2} \sum_{i=1}^n (x_i - \mu)^2
\end{aligned}
\]
Partial derivatives with respect to the parameters \(\boldsymbol{\theta} = (\mu, \sigma^2)\). The partial derivative of the log-likelihood with respect to the mean parameter for the \(x_i\) observation reads \[
\frac{\partial \ell_i(\mu, \sigma^2 \mid x_i)}{\partial \mu} = \frac{x_i - \mu}{\sigma^2}
\text{,}
\] and the total partial derivative reads \[
\frac{\partial \ell(\mu, \sigma^2 \mid \mathbf{x}_n)}{\partial \mu} = \frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \mu)
\text{.}
\] Similarly, the first derivative of the log-likelihood with respect to the variance parameter reads \[
\frac{\partial \ell_i(\mu, \sigma^2 \mid x_i)}{\partial \sigma^2} = -\frac{1}{2\sigma^2} + \frac{(x_i - \mu)^2}{2\sigma^4}
\text{,}
\] and the total partial derivative reads \[
\frac{\partial \ell(\mu, \sigma^2 \mid \mathbf{x}_n)}{\partial \sigma^2} =
-\frac{n}{2\sigma^2} + \frac{1}{2\sigma^4} \sum_{i=1}^n (x_i - \mu)^2
\text{.}
\]
Score vector: the complete score vector, reads \[
\nabla_{\ell}(\mu, \sigma^2 \mid \mathbf{x}_n)
=
\begin{pmatrix}
-\frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \mu) \\
-\frac{n}{2\sigma^2} + \frac{1}{2\sigma^4} \sum_{i=1}^n (x_i - \mu)^2
\end{pmatrix}
\text{.}
\] Notably, if \(X_i\) are truly Normal then the expected value of the gradient, the score, is zero, i.e. \[
\begin{aligned}
\mathbb{E}\{\nabla_{\ell}(\mu, \sigma^2 \mid \mathbf{X}_n)\} & {} =
\begin{pmatrix}
-\frac{1}{\sigma^2} \sum_{i=1}^n (\mathbb{E}\{x_i\} - \mu)
\\
-\frac{n}{2\sigma^2} + \frac{1}{\sigma^4} \sum_{i=1}^n \mathbb{E}\{(x_i - \mu)^2\}
\end{pmatrix} = \\
& = \begin{pmatrix}
-\frac{1}{\sigma^2} \sum_{i=1}^n (\mu - \mu)
\\
-\frac{n}{2\sigma^2} + \frac{1}{2\sigma^4} \sum_{i=1}^n \sigma^2
\end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix}
\end{aligned}
\] at the value of the true parameters \(\mu\), \(\sigma^2\), that is equivalent to say that the model is correctly specified.
To find the maximum likelihood estimates of the unknown parameters, one has to search for the values of \(\mu\) and \(\sigma^2\) such that the observed Score equations (Equation 11.3) are equal to zero. In general, this requires solving a system of first order conditions (Equation 11.6), i.e. \[
\nabla_{\ell} (\mu, \sigma^2 \mid \mathbf{x}_n) = 0
\iff
\begin{cases}
\frac{\partial \ell(\mu, \sigma^2 \mid \mathbf{x}_n)}{\partial \mu} = 0 \\
\frac{\partial \ell(\mu, \sigma^2 \mid \mathbf{x}_n)}{\partial \sigma^2} = 0
\end{cases}
\] Hence, one obtains a system of two equations in two unknowns. From the first equation depending on \(\mu\), the solution is exactly the sample mean, i.e. \[
\frac{\partial \ell(\mu, \sigma^2 \mid \mathbf{x}_n)}{\partial \mu} = 0 \implies \hat{\mu}^{\tiny \text{ML}} = \frac{1}{n} \sum_{i=1}^n x_i
\text{.}
\] Then, substituting \(\hat{\mu}^{\tiny \text{ML}}\) in the second equation gives \[
\frac{\partial \ell(\mu, \sigma^2 \mid \mathbf{x}_n)}{\partial \sigma^2} = 0
\implies \hat{\sigma}^{2\tiny \text{ML}} = \frac{1}{n} \sum_{i=1}^n (x_i - \hat{\mu}^{\tiny \text{ML}})^2
\text{.}
\] To compute the Hessian matrix (Equation 11.4), one has to make the second and cross derivatives explicit, i.e. \[
\begin{aligned}
{} & \partial^2_{\mu} \ell(\mu, \sigma^2 \mid \mathbf{x}_n) = -\frac{n}{\sigma^2} \text{,} \\
& \partial_{\sigma^2}^2 \ell(\mu, \sigma^2 \mid \mathbf{x}_n)
= \frac{n}{2\sigma^4}-\frac{1}{\sigma^6} \sum_{i=1}^n (x_i-\mu)^2 \text{,}
\end{aligned}
\] and the cross derivative in \(\mu\) and \(\sigma^2\), i.e. \[
\partial_{\sigma^2} \partial_{\mu} \ell(\mu, \sigma^2 \mid \mathbf{x}_n) = -\frac{1}{\sigma^4}\sum_{i=1}^n (x_i-\mu)
\text{.}
\] Therefore, the Jacobian matrix computed at the MLE estimate reads: \[
\mathbf{J}_{\ell}(\hat{\mu}^{\tiny \text{ML}}, \hat{\sigma}^{2\tiny \text{ML}} \mid \mathbf{x}_n) =
\begin{pmatrix}
-\dfrac{n}{ \sigma^{2\tiny MLE}} & 0\\
0 & \frac{n}{2 \hat{\sigma}^{4\tiny \text{ML}}} - \frac{1}{\hat{\sigma}^{6\tiny \text{ML}}}
\sum_{i=1}^n (x_i- \hat{\mu}^{\tiny \text{ML}})^2
\end{pmatrix}
\text{.}
\] since the cross derivative computed at the MLE estimate is equal to zero. Hence, taking the expectation, the Hessian matrix reads \[
\mathcal{H}(\hat{\mu}^{\tiny \text{ML}}, \hat{\sigma}^{2\tiny \text{ML}})=
\begin{pmatrix}
-\dfrac{n}{ \sigma^{2\tiny MLE}} & 0\\
0 & \frac{n}{2\hat{\sigma}^{4\tiny \text{ML}}}-\frac{n\hat{\sigma}^{2\tiny \text{ML}}}{\hat{\sigma}^{6\tiny \text{ML}}}
\end{pmatrix}
\text{.}
\] since, \(\sum_{i=1}^n (x_i-\hat{\mu}^{\tiny \text{ML}})^2 = n \hat{\sigma}^{2\tiny \text{ML}}\). Moreover, the first diagonal element is always less than zero, and also the second diagonal element, i.e. \[
\frac{n}{2\hat{\sigma}^{4\tiny \text{ML}}}-\frac{n\hat{\sigma}^{2\tiny \text{ML}}}{\hat{\sigma}^{6\tiny \text{ML}}} = -\frac{n}{2\hat{\sigma}^{4\tiny \text{ML}}}<0
\text{,}
\] Thus the Hessian is negative definite at the MLE, confirming a strict local maximum. Moreover, the theoretical Fisher information for \(n\) IID observations \[
\mathcal{I}(\hat{\mu}^{\tiny \text{ML}},\hat{\sigma}^{2\tiny \text{ML}}) =
-\mathcal{H}(\mu^{\tiny MLE}, \sigma^{2\tiny MLE}) =
\begin{pmatrix}
\dfrac{n}{\hat{\sigma}^{2\tiny \text{ML}}} & 0\\
0 & \dfrac{n}{2\hat{\sigma}^{4\tiny \text{ML}}}
\end{pmatrix}
\text{.}
\] is exactly \(n\)-times the Fisher Information of a single observation, i.e. \[
\mathcal{I}_{i}(\hat{\mu}^{\tiny \text{ML}},\hat{\sigma}^{2\tiny \text{ML}})=
\begin{pmatrix}
\dfrac{1}{\hat{\sigma}^{2\tiny \text{ML}}} & 0\\
0 & \dfrac{1}{2\hat{\sigma}^{4\tiny \text{ML}}}
\end{pmatrix}
\text{.}
\] Therefore, asymptotically, the MLE estimators are normally distributed, i.e. \[
\begin{pmatrix}
\hat{\mu}^{\tiny \text{ML}} \\\hat{\sigma}^{2\tiny \text{ML}}
\end{pmatrix}
\overset{\text{d}}{\underset{n\to\infty}{\sim}}
\text{MVN}_2
\left(
\begin{pmatrix}\mu \\ \sigma^2\end{pmatrix},
\frac{1}{n}
\begin{pmatrix}
\sigma^2 & 0 \\
0 & 2\sigma^4
\end{pmatrix}
\right)
\text{.}
\]
Example: Maximum likelihood estimate for a Normal
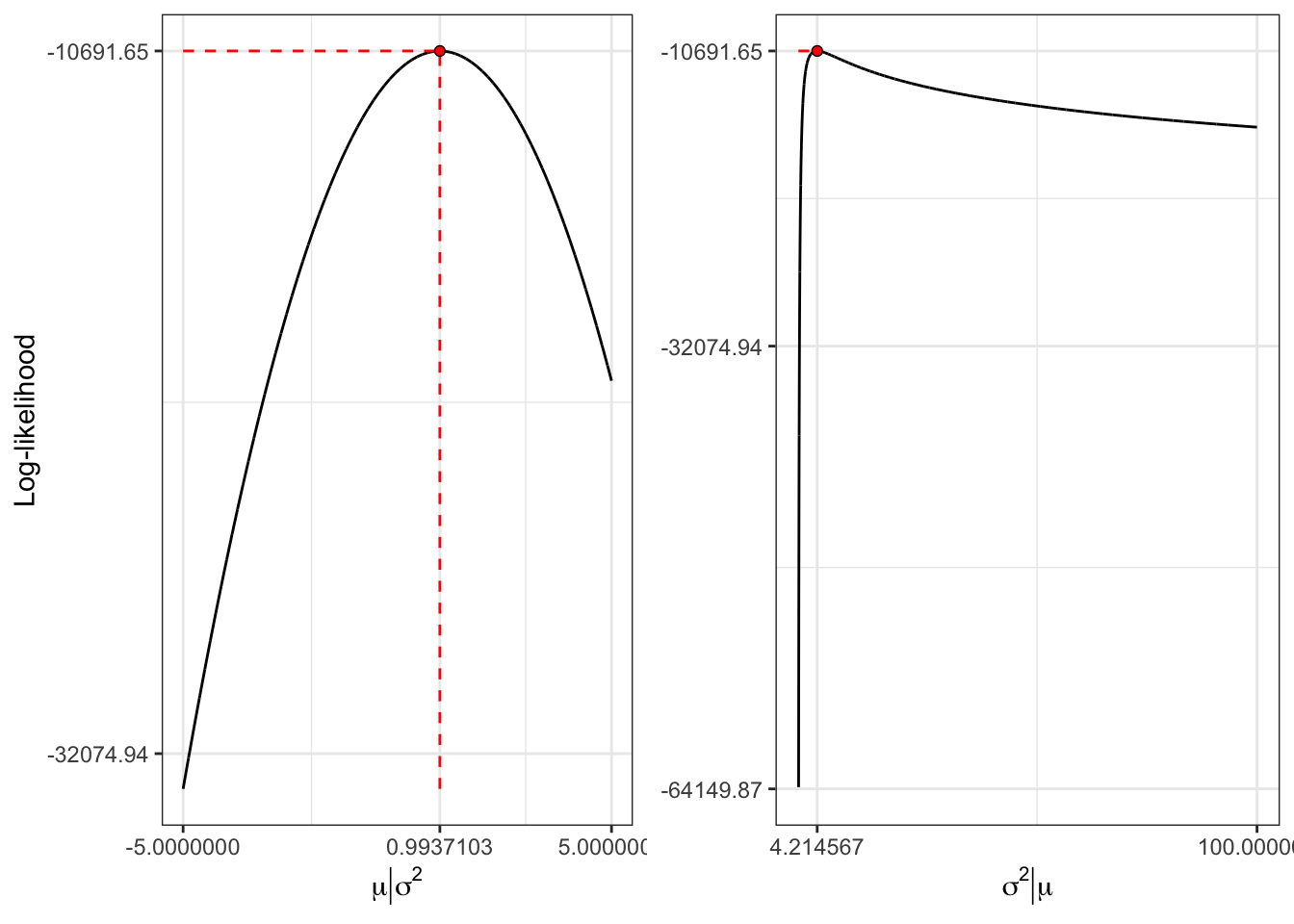
Example 11.1 Let’s simulate 5000 observations from an IID Normal distribution with mean \(\mu = 1\) and variance \(\sigma^2 = 4\). Then, given the simulated sample estimate the maximum likelihood parameters.
Maximum likelihood estimate
library(dplyr)library(purrr)################ inputs ################ set.seed(1)n_sim <-5000# number of simulations# true parameterspar <-c(mu =1, sigma2 =4)# normal sample x <-rnorm(n_sim, mean = par[1], sd =sqrt(par[2]))######################################### log-likelihood for a normal loglik_norm <-function(params, x){-sum(dnorm(x, mean = params[1], sd = params[2], log =TRUE))}# Numerical optimizationopt <-optim(c(0, 1), loglik_norm, x = x)# best mean parameter best_par <-tibble(mu = opt$par[1], sigma = opt$par[2], loglik =-opt$value)
\(\mu^{\tiny MLE}\)
\(\mu\)
Mean
\(\sigma\)
\(\sigma^{\tiny MLE}\)
Std.deviation
0.994
1
0.994
2
2.053
2.053
Table 11.1: Mean and std. deviation computed on the simulated sample and MLE estimates.
Figure 11.1: Log-likelihood function for a normal sample.
11.2 Quasi-Maximum Likelihood
Quasi-Maximum Likelihood Estimation (QMLE), also known as pseudo-maximum likelihood, is an estimation strategy used when the full distribution may be misspecified but a parametric likelihood can still be posited (e.g., correct conditional mean/variance form, wrong errors). In other words, we assume a parametric likelihood function for the data (perhaps incorrectly) and then maximize it as if it were true.
The QML estimator sacrifices some efficiency (if the model is misspecified there could exist estimators with a lower variance) for robustness: it converges to the pseudo-true parameter \(\boldsymbol{\theta}^{\star}\) (the best approximation within the assumed family), and valid inference follows from robust (sandwich) standard errors. This approach yields the quasi-MLE, an estimator that behaves like the true MLE under certain conditions but remains consistent even if the assumed distribution is wrong (See White (1982)).
11.2.1 QML Estimator
Let \(f_{\mathbf{X}_n}\) be the assumed parametric density function depending on the vector of parameters \(\boldsymbol{\theta}\). Then, even if the density \(f\) is misspecified, we define the pseudo-true parameter \(\boldsymbol{\theta}^{\star}\) as the value that maximizes the expected log-likelihood under the true distribution (see Gourieroux, Monfort, and Trognon (1984)), i.e. \[
\boldsymbol{\theta}^{\star} =
\underset{\boldsymbol{\theta} \in \Theta}{\arg \max} \;
\mathbb{E}\left\{\ell(\boldsymbol{\theta} \mid \mathbf{X}_n)\right\}
\text{,}
\] where the expectation is under the true data-generating process. In this case the log-likelihood used is also called pseudo-likelihood because we do not require to work under the true density. Equivalently, \(\boldsymbol{\theta}^{\star}\) is the value that minimizes the Kullback–Leibler (KL) distance between the true and the (possibly misspecified) parametric density. If the model is correctly specified, \(\boldsymbol{\theta}^{\star} = \boldsymbol{\theta}_0\) and QMLE coincides with MLE.
The QML estimator is the sample counterpart and maximizes the average log-likelihood given the realized sample \(\mathbf{x}_n\), i.e. \[
\hat{\boldsymbol{\theta}}^{\tiny \text{QML}}_n =
\underset{\boldsymbol{\theta} \in \Theta}{\arg \max} \;
\frac{1}{n}\sum_{i = 1}^{n} \mathcal{L}(\boldsymbol{\theta} \mid x_i)
\text{,}
\] Then, to find \(\hat{\boldsymbol{\theta}}^{\tiny \text{QML}}_n\) one proceeds exactly like ordinary MLE optimization finding the vector of parameters that maximizes the average log-likelihood.
11.2.2 Properties
Consistency of QMLE: Under the assumption that the model is identifiable at \(\hat{\boldsymbol{\theta}}^{\tiny \text{QML}}_n\), meaning that the expected log-likelihood has a unique maximum at \(\hat{\boldsymbol{\theta}}^{\tiny \text{QML}}_n\), and under standard regularity conditions (e.g. continuity of \(f(x;\theta)\) in \(\theta\)), the QMLE estimator converges in probability as \(n \to \infty\) to the pseudo-true parameter, i.e. \[
\hat{\boldsymbol{\theta}}^{\tiny \text{QML}}_n
\overset{\text{p}}{\underset{n \to \infty}{\longrightarrow}}
\boldsymbol{\theta}^{\star}
\text{.}
\] If the model is correctly specified, then the pseudo-true parameter coincides with the actual true parameter, i.e. \(\boldsymbol{\theta}^{\star} = \boldsymbol{\theta}_0\), and QMLE reduces to ordinary MLE. However, when the model is misspecified, the QMLE parameters converge to \(\boldsymbol{\theta}^{\star}\), which produces the best approximation of the true distribution, in the sense that it minimizes their KL distance.
Asymptotic normality: As the MLE, under regularity conditions, the QMLE is asymptotically normal. However, the asymptotic distribution must account for possible misspecification. More precisely, let’s define the expected information computed at the pseudo-true parameter as \[
\mathbf{A}(\boldsymbol{\theta}^{\star}) =
-\mathbb{E}\left\{
\mathbf{J}_{\ell}(\boldsymbol{\theta}^{\star} \mid \mathbf{X}_n)
\right\}
\] and \[
\mathbf{B}(\boldsymbol{\theta}^{\star}) = \mathbb{E}\left\{
\nabla_{\ell}(\boldsymbol{\theta}^{\star} \mid \mathbf{X}_n) \;
\nabla_{\ell}^{\top}(\boldsymbol{\theta}^{\star} \mid \mathbf{X}_n)
\right\}
\] Then, a result derived by Huber in the context of M-estimators and White in the context of misspecified likelihoods establishes that under misspecification \(\mathbf{A} \neq \mathbf{B}\) and the asymptotic variance is a sandwich of the two matrices, i.e. \[
\sqrt{n}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}} - \boldsymbol{\theta}^{\star})
\overset{\text{d}}{\underset{n \to \infty}{\rightarrow}}
\text{MVN}\left(\mathbf{0},
\mathbf{A}^{-1}(\boldsymbol{\theta}^{\star}) \mathbf{B}(\boldsymbol{\theta}^{\star}) \mathbf{A}^{-1}(\boldsymbol{\theta}^{\star})
\right)
\text{,}
\] If the model is correctly specified, then \(\boldsymbol{\theta}^{\star} = \boldsymbol{\theta}_0\) and one obtains \[
\mathbf{A}(\boldsymbol{\theta}_0) =
-\mathbb{E}\left\{
\mathbf{J}_{\ell}(\boldsymbol{\theta}_0 \mid \mathbf{X}_n) =
\right\}
= \mathbb{E}\left\{
\nabla_{\ell}(\boldsymbol{\theta}_0 \mid \mathbf{X}_n) \;
\nabla^{\top}_{\ell}(\boldsymbol{\theta}_0 \mid \mathbf{X}_n)
\right\} =
\mathbf{B}(\boldsymbol{\theta}_0)
\] In this case, the asymptotic variance simplifies and we recover the ML result that is asymptotically efficient. More precisely, the variance-covariance matrix of the QMLE \[
\mathbb{C}v\{\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}}\} = \mathbb{C}v\{\hat{\boldsymbol{\theta}}_n^{\tiny \text{ML}}\} = \mathbf{A}^{-1}(\boldsymbol{\theta}_0)
\] A noteworthy point is that QMLE is generally not fully efficient if the model is misspecified: there might exist other estimators targeting the same quantity that have smaller asymptotic variance if one knew more about the true distribution. But QMLE has the convenience of likelihood-based estimation and retains consistency and asymptotic normality without needing the full truth.
11.2.3 Sandwich Standard Errors
Given the asymptotic variance formula above, a crucial practical issue is how to compute standard errors for QMLE estimates. If one naively computes standard errors as if the assumed model were true (for example, using just the inverse Hessian), the inference can be invalid when the model is misspecified. The remedy is to use robust or sandwich standard errors, often called heteroskedasticity-consistent standard errors in econometrics (See White (1980)).
In practice, to compute the robust variance estimate, one proceeds as follows:
First, obtain the QMLE parameters \(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}}\) by maximizing the pseudo log-likelihood.
Secondly, compute the average observed Information matrix at the estimated parameter, i.e. \[
\hat{\mathbf{A}}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}}) =
-\frac{1}{n}\sum_{i=1}^n
\mathbf{J}_{\ell}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}} \mid \mathbf{x}_n)
\]
Compute the outer product of gradients matrix at the QMLE: \[
\hat{\mathbf{B}}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}}) =
\frac{1}{n}\sum_{t=1}^n
\nabla_{\ell}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}} \mid \mathbf{x}_n) \;
\nabla_{\ell}^{\top}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}} \mid \mathbf{x}_n)
\] This uses the scores for each observation and does not assume the model is correct. Hence, the estimated variance-covariance matrix of the QML parameters reads: \[
\mathbb{C}v\{\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}}\} =
\frac{1}{n}
\hat{\mathbf{A}}^{-1}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}})
\hat{\mathbf{B}}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}})
\hat{\mathbf{A}}^{-1}(\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}})
\] where the diagonal elements (scaled by \(1/n\)) give the variance estimates for each parameter, while the off-diagonal elements give their covariances. Therefore, the variances are obtained as \[
\mathbb{V}\{\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}}\} =
\frac{1}{n}\text{diag}\left(\mathbb{C}v\{\hat{\boldsymbol{\theta}}_n^{\tiny \text{QML}}\}\right)
\] if \(\hat{\mathbf{A}}\) and \(\hat{\mathbf{B}}\) were computed as averages, or without rescaling if they are summed forms.
If the model is actually correctly specified, then \(\hat{\mathbf{B}}\) should be close to \(\hat{\mathbf{A}}\) in large samples, and the variance reduces to the usual Fisher information based variance \(\hat{\mathbf{A}}^{-1}\). Thus, the robust variance estimator is a conservative generalization: it equals the classical one in the ideal case, but remains valid in the non-ideal case.
Gourieroux, Christian, Alain Monfort, and Alain Trognon. 1984. “Pseudo Maximum Likelihood Methods: Theory.”Econometrica 52 (3): 681–700. https://www.jstor.org/stable/1913471.
White, Halbert. 1980. “A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity.”Econometrica 48 (4): 817–38. https://doi.org/10.2307/1912934.