14 Introduction
Statistical modeling applies statistical methods to real-world data to give empirical content to relationships. It aims to quantify phenomena and develop models and test hypotheses, making it a crucial field for economic research, policy analysis, and decision-making. The aim of the statistical modeling is to study the (unknown) mechanism that generates the data, i.e., the Data Generating Process (DGP). The statistical model is a function that approximates the DGP.
14.1 The matrix of data
Let’s consider \(n\) realizations defining a sample for \(i = 1, 2, \ldots, n\). Suppose we have \(p\) dependent variables and \(k\) explanatory variables (also known as predictors). The data matrix of the exogenous variables (regressors) \(\mathbf{X}_{n,k}\) is defined as in Equation 13.1, while the matrix composed of the endogenous variables (dependent variables) \(\mathbf{Y}\) reads \[ \underset{n \times p}{\mathbf{Y}} = \begin{pmatrix} y_{1,1} & y_{1,2} & \dots & y_{1,j} & \dots & y_{1,p} \\ y_{2,1} & y_{2,2} & \dots & y_{2,j} & \dots & y_{2,p} \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots \\ y_{n,1} & y_{n,2} & \dots & y_{n,j} & \dots & y_{n,p} \end{pmatrix} \text{.} \] Hence, the complete matrix of data reads \[ \underset{n \times (k + p)}{\mathbf{W}} = \begin{pmatrix} \mathbf{Y} & \mathbf{X} \end{pmatrix} = \begin{pmatrix} y_{1,1} & \dots & y_{1,p} & x_{1,1} & \dots & x_{1,k} \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ y_{n,1} & \dots & y_{n,p} & x_{n,1} & \dots & x_{n,k} \\ \end{pmatrix} \text{.} \tag{14.1}\] In general, when \(p = 1\) then the model has only one equation to satisfy for \(i = 1, \dots, n\), for example \[ Y_{i} = b_0 + b_1 x_{i, 1} + b_2 x_{i, 2} + \dots + b_k x_{i, k} + u_i \text{.} \tag{14.2}\] Otherwise, when \(p > 1\) there is more than one dependent variable and the model is composed of \(p\) equations for \(i = 1, \dots, n\), i.e. the same linear model with \(p\) equations reads: \[ \begin{cases} Y_{i,1} = b_{0, 1} + b_{1, 1} x_{i, 1} + b_{1, 2} x_{i, 2} + \dots + b_{1, k} x_{i, k} + u_{i,1} \\ Y_{i,2} = b_{0, 2} + b_{2, 1} x_{i, 1} + b_{2, 2} x_{i, 2} + \dots + b_{2, k} x_{i, k} + u_{i,2} \\ \vdots \\ Y_{i,p} = b_{0, p} + b_{p, 1} x_{i, 1} + b_{p, 2} x_{i, 2} + \dots +b_{p, k} x_{i, k} + u_{i,p} \end{cases} \tag{14.3}\] Thus, the matrix of the residual components reads \[ \underset{n \times p}{\mathbf{U}} = \begin{pmatrix} u_{1,1} & u_{1,2} & \dots & u_{1,i} & \dots & u_{1,p} \\ u_{2,1} & u_{2,2} & \dots & u_{2,i} & \dots & u_{2,p} \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots \\ u_{n,1} & u_{n,2} & \dots & u_{n,i} & \dots & u_{n,p} \end{pmatrix} \text{,} \]
14.2 Joint, conditional and marginals
Let’s consider the bi-dimensional random vector in Equation 14.1 and let’s write the joint distribution of \(\mathbf{X}\) and \(\mathbf{Y}\), i.e. \[
\underset{\text{joint probability}}{\mathbb{P}(\mathbf{Y}_1, \dots, \mathbf{Y}_p \le \mathbf{y}_1, \dots, \mathbf{y}_p, \mathbf{X}_1, \dots, \mathbf{X}_p \le \mathbf{x}_1, \dots, \mathbf{x}_k}) = \underset{\text{distribution function}}{F_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}_1, \dots, \mathbf{y}_p, \mathbf{x}_1, \dots, \mathbf{x}_k})
\text{.}
\tag{14.4}\] In the continuous case, there exists a joint density \(f_{\mathbf{Y}, \mathbf{X}}\) such that: \[
F_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x}) = \int_{-\infty}^{\mathbf{x}} \int_{-\infty}^{\mathbf{y}} f_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x}) d\mathbf{y} d\mathbf{x}
\text{.}
\tag{14.5}\] Moreover, from the joint distribution (Equation 14.4) it is possible to recover the marginal distributions, i.e.
\[
\begin{aligned}
& {} f_{\mathbf{Y}}(\mathbf{y}) = \partial_{\mathbf{y}} F_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x}) = \int_{-\infty}^{\infty} f_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x}) d\mathbf{x} \text{,} \\
& f_{\mathbf{X}}(\mathbf{x}) = \partial_{\mathbf{x}} F_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x}) = \int_{-\infty}^{\infty} f_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x}) d\mathbf{y} \text{.}
\end{aligned}
\tag{14.6}\]
Then, given the marginals (Equation 14.6), it is possible to compute the unconditional moments, for example
- First moment: \(\mathbb{E}\{\mathbf{Y}\} = \int_{-\infty}^{\infty} \mathbf{y} f_{\mathbf{Y}}(\mathbf{y})d\mathbf{y}\).
- Second moment: \(\mathbb{E}\{\mathbf{Y}^2\} = \int_{-\infty}^{\infty} \mathbf{y}^2 f_{\mathbf{Y}}(\mathbf{y})d\mathbf{y}\).
Applying the Bayes theorem (Theorem 6.2), from the joint distribution (Equation 14.4) it is possible to recover the conditional distribution, i.e
\[
f_{\mathbf{Y} \mid \mathbf{X}}(\mathbf{y} \mid \mathbf{x}) =
\frac{f_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x})}{f_{\mathbf{X}}(\mathbf{x})}
\iff
\underset{\text{joint}}{f_{\mathbf{Y}, \mathbf{X}}(\mathbf{y}, \mathbf{x})} =
\underset{\text{conditional}}{f_{\mathbf{Y} \mid \mathbf{X}}(\mathbf{y} \mid \mathbf{x})} \cdot \underset{\text{marginal}}{f_{\mathbf{X}}(\mathbf{x})}
\text{.}
\tag{14.7}\] Given the conditional distribution, the conditional moments read \[
\begin{aligned}
{} & \mathbb{E}\{\mathbf{Y} \mid \mathbf{X}\} = \int_{-\infty}^{\infty} \mathbf{y} f_{\mathbf{Y} \mid \mathbf{X}}(\mathbf{y} \mid \mathbf{x})d\mathbf{y} \text{,} \\
& \mathbb{E}\{\mathbf{Y}^2 \mid \mathbf{X}\} = \int_{-\infty}^{\infty} \mathbf{y}^2 f_{\mathbf{Y} \mid \mathbf{X}}(\mathbf{y} \mid \mathbf{x})d\mathbf{y} \text{.}
\end{aligned}
\]
Example: Inference on a Multivariate Gaussian model
Example 14.1 Let’s consider a multivariate Gaussian setup, i.e. \[ \begin{pmatrix} \mathbf{Y} \\ \mathbf{X} \end{pmatrix} \sim \text{MVN} \left( \begin{pmatrix} \boldsymbol{\mu}_{\mathbf{Y}} \\ \boldsymbol{\mu}_{\mathbf{X}} \end{pmatrix}, \begin{pmatrix} \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{Y}} & \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{X}} \\ \boldsymbol{\mu}_{\mathbf{X}\mathbf{Y}} & \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}} \end{pmatrix} \right) \text{.} \] If \((\mathbf{X} \; \mathbf{Y})\) are jointly normal, then the marginals are multivariate normal, i.e. \[ \mathbf{Y} \sim \text{MVN}(\boldsymbol{\mu}_{\mathbf{Y}}, \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{Y}}) \text{,} \quad \mathbf{X} \sim \text{MVN}(\boldsymbol{\mu}_{\mathbf{X}}, \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}}) \text{,} \] and also the conditional distributions, i.e. \[ \mathbf{Y} \mid \mathbf{X} \sim \text{MVN}(\boldsymbol{\mu}_{\mathbf{Y \mid \mathbf{X}}}, \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{Y} \mid \mathbf{X}}) \text{,} \quad \mathbf{X} \mid \mathbf{Y} \sim \text{MVN}(\boldsymbol{\mu}_{\mathbf{X} \mid \mathbf{Y}}, \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X} \mid \mathbf{Y}}) \text{.} \] In such a model setup, the conditional expectation of \(\mathbf{Y}\) given \(\mathbf{X}\) reads \[ \begin{aligned} \mathbb{E}\{\mathbf{Y} \mid \mathbf{X}\} & {} = \boldsymbol{\mu}_{\mathbf{Y \mid \mathbf{X}}} = \\ & = \boldsymbol{\mu}_{\mathbf{Y}} + \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{X}} \cdot \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}}^{-1}(\mathbf{X} - \boldsymbol{\mu}_{\mathbf{X}}) = \\ & = \boldsymbol{\mu}_{\mathbf{Y}} - \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{X}} \cdot \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}}^{-1} \, \boldsymbol{\mu}_{\mathbf{X}} + \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{X}} \cdot \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}}^{-1} \, \mathbf{X} = \\ & = \boldsymbol{\mu}_{\mathbf{Y}} - \mathbf{b}_{\mathbf{Y} \mid \mathbf{X}} \, \boldsymbol{\mu}_{\mathbf{X}} + \mathbf{b}_{\mathbf{Y} \mid \mathbf{X}} \, \mathbf{X} = \\ & = \mathbf{a}_{\mathbf{Y} \mid \mathbf{X}} + \mathbf{b}_{\mathbf{Y} \mid \mathbf{X}} \, \mathbf{X} \end{aligned} \] and the conditional variance as \[ \mathbb{V}\{\mathbf{Y} \mid \mathbf{X}\} = \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{Y}} - \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{X}} \cdot \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}}^{-1}\boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{X}} \text{.} \] In this setup the parameters are:
- Joint distribution, \(\boldsymbol{\theta} = \{\boldsymbol{\mu}_{\mathbf{Y}}, \boldsymbol{\mu}_{\mathbf{X}}, \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}}, \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{Y}}, \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{Y}} \}\).
- Conditional distribution, \(\boldsymbol{\lambda}_1 = \{\mathbf{a}_{\mathbf{Y} \mid \mathbf{X}}, \mathbf{b}_{\mathbf{Y} \mid \mathbf{X}}, \boldsymbol{\Sigma}_{\mathbf{Y}\mathbf{Y} \mid \mathbf{X}} \}\).
- Marginal distribution, \(\boldsymbol{\lambda}_2 = \{\boldsymbol{\mu}_{\mathbf{X}}, \boldsymbol{\Sigma}_{\mathbf{X}\mathbf{X}} \}\).
Noting that \(\boldsymbol{\lambda}_1\) is a function of \(\boldsymbol{\theta}\), i.e. \(\tau = f(\boldsymbol{\lambda}_1)\), in the Gaussian case it is possible to prove that \(\boldsymbol{\lambda}_1\) and \(\boldsymbol{\lambda}_2\) are free to vary. Hence, imposing restrictions on \(\boldsymbol{\lambda}_1\) does not impose restrictions on \(\boldsymbol{\lambda}_2\). In general, if the parameters of interest are a function of the conditional distribution and \(\boldsymbol{\lambda}_1\) and \(\boldsymbol{\lambda}_2\) are free to vary, then the inference can be done without losing information by considering the conditional model. In this case we say that \(\mathbf{X}\) is weakly exogenous for \(\tau = f(\boldsymbol{\lambda}_1)\).
14.3 Conditional expectation model
Let’s consider a very general conditional expectation model with \(p = 1\), of which the linear models are a special case. In matrix notation it can be written as: \[ \mathbf{y} = \mathbb{E}\{\mathbf{y} \mid \mathbf{X}\} + \mathbf{u} \text{,} \tag{14.8}\] where the conditional expectation errors are defined as: \[ \mathbf{u} = \mathbf{y} - \mathbb{E}\{\mathbf{y} \mid \mathbf{X}\} \text{.} \tag{14.9}\]
Proposition 14.1 In a conditional expectation model as in Equation 14.8, the residuals \(\mathbf{u}\), defined as in Equation 14.9, have unconditional expectation and covariance with the regressors \(\mathbf{X}\) equal to zero, i.e. \[ \mathbb{E}\{\mathbf{u}\} = 0, \quad \mathbb{E}\{\mathbf{u}\mathbf{X} \} = 0 \text{.} \] Moreover, the conditional expectation error is orthogonal to any transformation of the conditioning variables, i.e. \[ \mathbf{y} = \mathbb{E}\{\mathbf{y} \mid g(\mathbf{X})\} + \mathbf{u} \implies \mathbb{E}\{\mathbf{u} \, g(\mathbf{X}) \} = 0 \text{.} \tag{14.10}\]
14.4 Uniequational linear models
Let’s consider a uni-equational linear model, i.e. with \(p = 1\) in (Equation 14.2), expressed in compact matrix notation as: \[ \underset{n \times 1}{\mathbf{y}} = \underset{n \times k}{\mathbf{X}} \; \underset{k \times 1}{\mathbf{b}} + \underset{n \times 1}{\mathbf{u}} \text{,} \tag{14.11}\] where \(\mathbf{b}\) and \(\mathbf{u}\) represent the true parameters and residuals in the population. Let’s consider a sample of \(n\) observations extracted from a population; then the matrix of the regressors \(\mathbf{X}\) reads as in Equation 13.1, while the vectors of the dependent variable and of the residuals read \[ \underset{n \times 1}{\mathbf{y}} = \begin{pmatrix} y_{1} \\ \vdots \\ y_{n} \end{pmatrix} \text{,} \quad \underset{n \times 1}{\mathbf{u}} = \begin{pmatrix} u_{1} \\ \vdots \\ u_{n} \end{pmatrix} \text{.} \] Hence, the matrix of data \(\mathbf{W}\) is composed of: \[ \begin{pmatrix} \mathbf{y} & \mathbf{X} \end{pmatrix} = \begin{pmatrix} y_{1} & x_{1,1} & \dots & x_{1,k} \\ \vdots & \vdots & \ddots & \vdots \\ y_{n} & x_{n,1} & \dots & x_{n, k} \\ \end{pmatrix} \text{.} \tag{14.12}\]
14.4.1 Estimators of b
In general, the true population parameter \(\mathbf{b}\) is unknown and lives in the parameter space, i.e. \(\mathbf{b} \in \Theta_{\mathbf{b}} \subset \mathbb{R}^k\). In the following section we will define with \(Q\) the estimator function while \(\hat{\mathbf{b}}\) will denote one of its possible estimates.
Depending on the specification of the model, the function \(Q\) takes as input the matrix of data and returns as output a vector of estimates, i.e. \[ Q: \mathbf{W} \longrightarrow \Theta_{\mathbf{b}}, \quad\text{such that}\quad Q(\mathbf{W}) = \hat{\mathbf{b}} \in \Theta_{\mathbf{b}} \text{.} \] In this context, the fitted values \(\hat{\mathbf{y}}\) can be seen as a function of the estimate \(\hat{\mathbf{b}}\), i.e. \[ \hat{\mathbf{y}}(\hat{\mathbf{b}}) = \mathbf{X} \hat{\mathbf{b}} \text{.} \tag{14.13}\] Consequently, the fitted residuals \(\hat{\mathbf{u}}\), which measure the discrepancies between the observed and the fitted values, are also a function of \(\mathbf{b}\), i.e. \[ \hat{\mathbf{u}}(\hat{\mathbf{b}}) = \mathbf{y} - \hat{\mathbf{y}}(\hat{\mathbf{b}}) = \mathbf{y} - \mathbf{X}\hat{\mathbf{b}} \text{.} \tag{14.14}\]
Different optimal estimators of \(\mathbf{b}\)
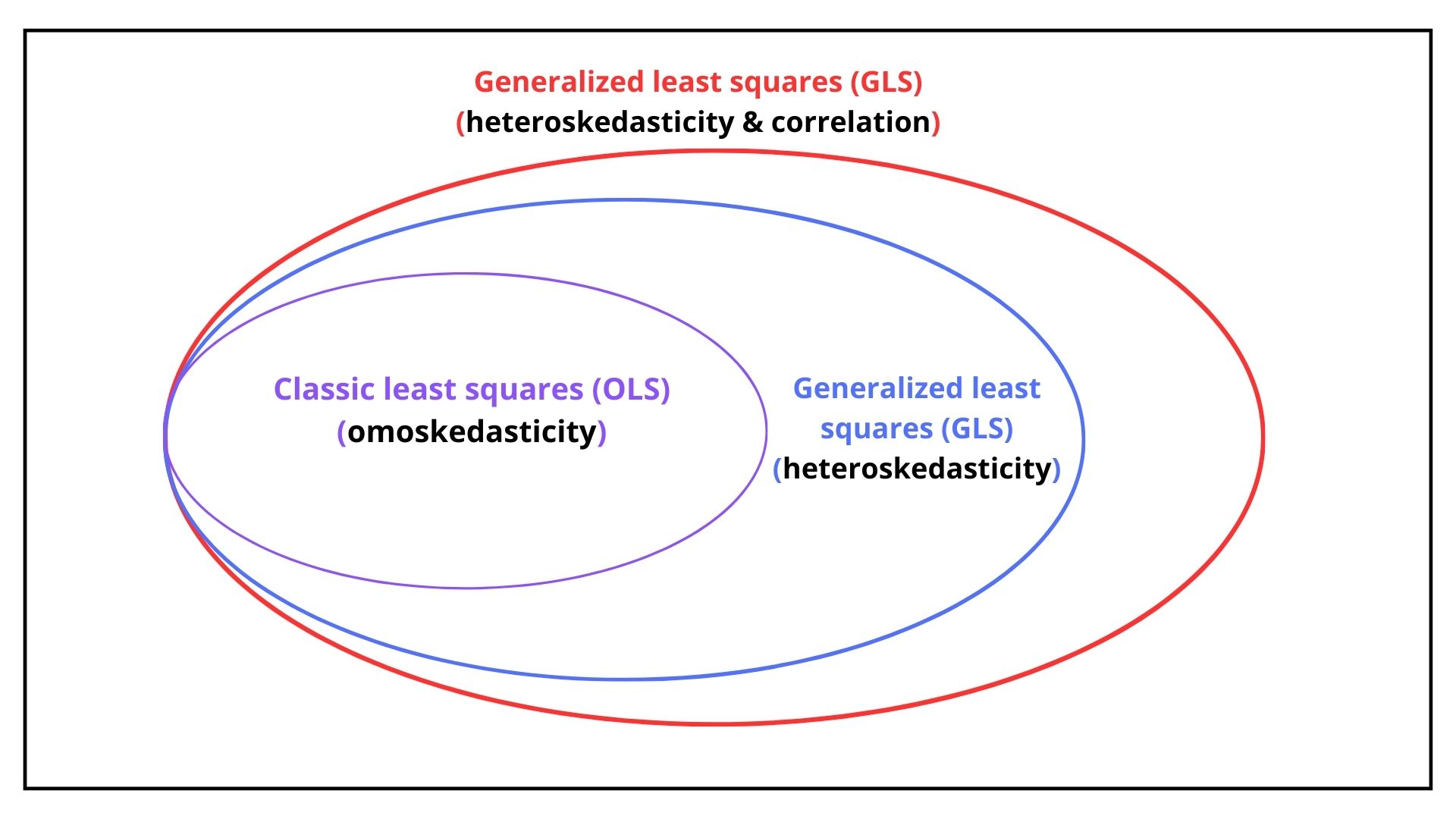
As we will see in Chapter 15, the assumptions on the variance of the residuals determine the optimal estimator of \(\mathbf{b}\). In general, the residuals could be
- homoskedastic: the residuals are uncorrelated and their variance is equal for each observation.
- heteroskedastic: the residuals are uncorrelated and their variance is different for each observation.
- autocorrelated: the residuals are correlated and their variance can differ across observations.
As shown in Figure 14.1, depending on the assumption (1, 2 or 3), the optimal estimator of \(\mathbf{b}\) is obtained with Ordinary Least Squares for case 1, while Generalized Least Squares is used for cases 2 and 3.
For example, if the residuals are correlated, then their conditional variance-covariance matrix reads \[
\boldsymbol{\Sigma} = \mathbb{V}\{\mathbf{u} \mathbf{u}^{\top} \mid \mathbf{X}\}
\text{,}
\] or more explicitly,
\[
\underset{n \times n}{\boldsymbol{\Sigma}}=
\begin{pmatrix}
u_{1}^2 & u_{1} u_2 & \dots & u_{1} u_n \\
u_{2} e_1 & u_{2}^2 & \dots & u_{2} u_n \\
\vdots & \vdots & & \vdots \\
u_{n} e_1 & u_{n} u_{2} & \dots & u_{n}^2
\end{pmatrix}
=
\begin{pmatrix}
\sigma^{2}_{1} & \sigma_{1,2} & \dots & \sigma_{1,n} \\
\sigma_{2,1} & \sigma^{2}_{2} & \dots & \sigma_{2,n} \\
\vdots & \vdots & & \vdots \\
\sigma_{n,1} & \sigma_{n,2} & \dots & \sigma^{2}_{n}
\end{pmatrix}
\text{.}
\tag{14.15}\] Since the matrix \(\boldsymbol{\Sigma}\) is symmetric, the number of distinct elements above (or below) the diagonal reads \[
\binom{n}{2} = \frac{n(n-1)}{2}
\text{.}
\] Hence, given that the number of elements of \(\boldsymbol{\Sigma}\) is \(n\times n\), the number of unique values (free elements) is given by the \(n\) variances plus \(\frac{n(n-1)}{2}\) covariances, i.e. \[
\text{free elements} = n + \frac{n(n-1)}{2} = \frac{n(n+1)}{2} > n
\text{.}
\]