A stochastic process is a collection of random variables \(\{X_t\}_{t \in \mathcal{T}}\) defined on a probability space \((\Omega, \mathcal{B}, \mathbb{P})\) and assuming values in \(\mathbb{R}^k\) with \(k \ge 1\). The index set \(\mathcal{T}\) is usually the half-line \([0, \infty)\), but can also be an interval \([a, b]\) or a subset of \(\mathbb{R}^k\).
While a stochastic process has a clear mathematical definition, a time series is a less precise notion, and people use it to refer to two related but different objects. A time series can be seen as a stochastic process indexed by integers or by some regular unit of time that can be mapped to integers (e.g., minutely, hourly, daily, or monthly data). A time series can also be understood as a collection of time-value data-point pairs, while a stochastic process is the mathematical description of a distribution of time series. Some time series are realizations of stochastic processes, or one can use a stochastic process as a model to generate a time series.
Definition 18.1 (Filtration) Let \((\Omega, \mathcal{B}, \mathbb{P})\) be a probability space and let \(\mathcal{T}\) be an index set. If for every \(t \in \mathcal{T}\) one has that \(\mathcal{F}_t\) is a sub-\(\sigma\)-algebra of \(\mathcal{B}\) and for every \(k \le t\) it holds that \(\mathcal{F}_k \subseteq \mathcal{F}_t\), then the family of sub-\(\sigma\)-algebras denoted by \[
\{\mathcal{F}_t\}_{t \in \mathcal{T}}
\text{,}
\] is called a filtration.
For example, consider a stochastic process \(\{X_n\}_{n \in \mathbb{N}}\) and the sequence of sub-\(\sigma\)-algebras generated by \(X_1, X_2, \dots, X_n\). Then \(\mathcal{F}_n\) is a \(\sigma\)-algebra and \(\{\mathcal{F}_n\}_{n \in \mathbb{N}}\) is a filtration, also called the natural filtration, with respect to \(\{X_n\}_{n \in \mathbb{N}}\). Formally, \(\mathcal{F}_n\) is the smallest \(\sigma\)-algebra containing all events observable up to the index \(n\), i.e. \[
\begin{aligned}
{}
& \mathcal{F}_0 = \sigma(X_0) \\
& \mathcal{F}_1 = \sigma(\mathcal{F}_0 \cup \sigma(X_1)) = \sigma(X_0, X_1) \\
& \mathcal{F}_2 = \sigma(\mathcal{F}_1 \cup \sigma(X_2)) = \sigma(X_0, X_1, X_2) \\
& \; \vdots \\
& \mathcal{F}_n = \sigma(\mathcal{F}_{n-1} \cup \sigma(X_n)) = \sigma(X_0, X_1, X_2, \dots, X_n) \\
\end{aligned}
\]
18.1 Stationarity
Definition 18.2 (Strongly stationary) A stochastic process \(\{X_t\}_{t\in\mathcal{T}}\) is said to be strongly stationary if and only if for all finite collections of indices \(t_1, t_2, \dots, t_n \in \mathcal{T}\) and every shift \(h\) such that \(t_1+h, \dots, t_n+h \in \mathcal{T}\), \[
\mathbb{P}(X_{t_1}, X_{t_2}, \dots, X_{t_n}) = \mathbb{P}(X_{t_1+h}, X_{t_2+h}, \dots, X_{t_n+h})
\text{.}
\] meaning that the joint distribution of an arbitrary number of random variables \(X_{t_1}, X_{t_2}, \dots, X_{t_n}\) does not change when shifting the process, upward or downward, by a step \(h\).
Definition 18.3 (Weakly stationary) A stochastic process \(\{X_t\}_{t\in\mathcal{T}}\) is said to be weakly stationary (or covariance stationary) if and only if
\(\mathbb{E}\{X_t\} = \mu\) and \(|\mu|< \infty\) for every \(t \in \mathcal{T}\);
\(\mathbb{E}\{X_t^2\} < \infty\) for every \(t \in \mathcal{T}\);
\(\mathbb{C}v\{X_t, X_{t+h}\} = \gamma(h)\) and \(|\gamma(h)|< \infty\) for every \(t \in \mathcal{T}\) and every admissible lag \(h\).
Hence, the covariance \(\gamma(h)\) of a weakly stationary process does not depend on time \(t\), but only on the temporal lag \(h\) between two observations.
Strong and weak stationarity
In general, strong stationarity (Definition 18.2) does not imply weak stationarity unless the second moment is finite. For example, an independent and identically distributed Cauchy process is strongly stationary, but since its expectation and variance are not finite, the process is not weakly stationary. Conversely, weak stationarity does not imply strong stationarity, because it controls only the first two moments and not the full joint distribution.
18.2 Notable processes
Definition 18.4 (IID process) A time series \(\{X_t\}_{t\in\mathcal{T}}\) where each \(X_t\) is independent from the others and all \(X_t\) have the same distribution for all \(t\) is called an independent and identically distributed process (IID). Such a process, usually denoted as \(X_t \sim \text{IID}(0, \sigma^2)\), is strongly stationary (Definition 18.2). Moreover, if the mean and variance are finite, the covariance is zero and the process is also weakly stationary (Definition 18.3), i.e. \[
\gamma_t(h) = \mathbb{C}v\{X_t, X_{t+h}\} = \mathbb{E}\{X_t X_{t+h}\} = \mathbb{E}\{X_t\} \mathbb{E}\{X_{t+h}\} = 0, \qquad h \ne 0
\text{.}
\]
Definition 18.5 (White noise) A stochastic process \(\{X_t\}_{t \in \mathcal{T}}\), commonly denoted as \[
X_t \sim \text{WN}(0, \sigma^2)
\text{.}
\tag{18.1}\] is called White Noise if it satisfies the following properties:
The expectation is equal to zero, i.e. \(\mathbb{E}\{X_t\} = 0\) for all \(t \in \mathcal{T}\).
The variance is finite and constant for all \(t \in \mathcal{T}\), i.e. \(\mathbb{V}\{X_t\} = \sigma^2 < \infty\).
The process is uncorrelated over time for all \(t \ne k\), i.e. \(\mathbb{C}v\{X_t, X_k\} = 0\).
A White Noise process is weakly stationary (Definition 18.3). In fact, the autocovariance function of the process depends on the lag, but not on time, i.e. it is equal to the variance for \(t = s\) and is zero otherwise. This process is more general than an IID process (Definition 18.4), since it does not require the stochastic independence of the time series for all \(t\).
18.2.1 Martingales
Definition 18.6 (Martingale) Let’s consider a probability space \((\Omega, \mathcal{B}, \mathbb{P})\) and stochastic process \(\{M_t\}_{t \in \mathcal{T}}\). Then, given a filtration \(\mathcal{F}\), namely \(\{\mathcal{F}_t\}_{t \in \mathcal{T}}\), the stochastic process \(M_t\) is a martingale with respect to the filtration \(\{\mathcal{F}_t\}_{t \in \mathcal{T}}\) if
\(M_t\) is adapted to \(\mathcal{F}_t\) in the sense that \(M_t\) is included in the information contained in \(\mathcal{F}_t\), i.e. \(M_t\) is \(\mathcal{F}_t\)-measurable.
\(\mathbb{E}\{|M_t|\}<\infty\) for every \(t\).
For any \(0 \le k < t\)\[
\mathbb{E}\{M_t \mid \mathcal{F}_{k}\} = M_k
\text{.}
\tag{18.2}\]
Definition 18.7 (Martingale difference sequence) Let’s consider a probability space \((\Omega, \mathcal{B}, \mathbb{P})\) and stochastic process \(\{D_t\}_{t \in \mathcal{T}}\). Then, given a filtration \(\mathcal{F}\), namely \(\{\mathcal{F}_t\}_{t \in \mathcal{T}}\), the stochastic process \(D_t\) is a martingale difference sequence (MDS) with respect to the filtration \(\{\mathcal{F}_t\}_{t \in \mathcal{T}}\) if \(D_t\) is integrable, \(\mathcal{F}_t\)-measurable and for any \(0 \le k < t\)\[
\mathbb{E}\{D_t \mid \mathcal{F}_{k}\} = 0
\text{.}
\tag{18.3}\] This implies that \(D_t\) is a mean-zero process uncorrelated with any information contained in \(\mathcal{F}_{t-1}\). The definition can be extended to a case where the filtration \(\mathcal{F}_{t-1}\) also includes other processes \(X_t\). In this case, \(D_t\) is said to be an MDS conditional on\(X_t\) if the same condition in Equation 18.3 holds.
Super and sub-martingales
A stochastic process \(\{X_t\}_{t \in \mathcal{T}}\) is said to be a sub-martingale if instead of Equation 18.2 we have that for any \(0 \le k < t\), \[
\mathbb{E}\{X_t \mid \mathcal{F}_{k}\} \ge X_k
\text{.}
\tag{18.4}\] On the other hand it is said to be a super-martingale if \[
\mathbb{E}\{X_t \mid \mathcal{F}_{k}\} \le X_k
\text{.}
\tag{18.5}\] From the above definitions, it follows that to be a martingale (or an MDS) a stochastic process must be both a super-martingale and a sub-martingale.
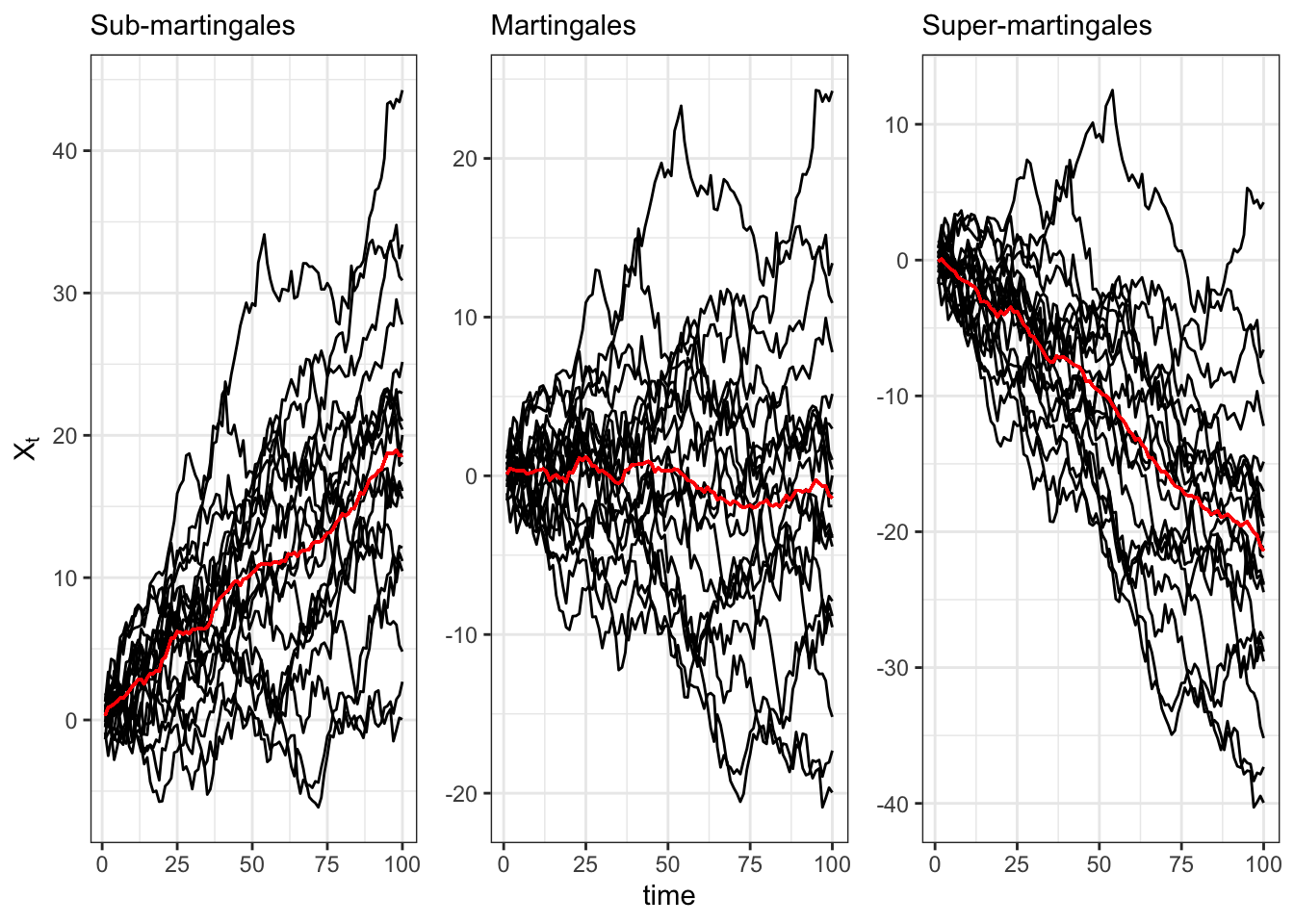
Simulate Martingales
set.seed(1)# Number of observationsN <-100# Number of simulationsj_bar <-20# Predictable processA_t <-rep(0.2, N)X_sub <- X_mar <- X_sup <-list()for(j in1:j_bar){# Martingale M_t <-rnorm(N, 0, 1)# Sub-martingale X_sub[[j]] <- dplyr::tibble(j = j, t =1:N, X =cumsum(A_t + M_t))# Martingale X_mar[[j]] <- dplyr::tibble(j = j, t =1:N, X =cumsum(M_t))# Super-martingale X_sup[[j]] <- dplyr::tibble(j = j, t =1:N, X =cumsum(-A_t + M_t))}
Figure 18.1: Simulation of a sub-martingale, martingale and super-martingale with expected value (red).
The concept of martingales is connected to the concept of predictability of a stochastic process.
Definition 18.8 (Predictable process) Let’s consider a probability space \((\Omega, \mathcal{B}, \mathbb{P})\) and stochastic process \(\{A_t\}_{t \in \mathcal{T}}\). Then, let’s define a sequence of sub-\(\sigma\) fields of \(\mathcal{B}\), namely \(\{\mathcal{F}_t\}_{t \in \mathcal{T}}\). Then, the stochastic process \(A_t\) is predictable if
\(A_0 \in \mathcal{F}_0\);
For any \(t \ge 0\) we have that \(A_{t+1} \in \mathcal{F}_t\).
Then, we call the process predictable and increasing if \(0 = A_0 \le A_1 \le A_2 \le \dots\).
Theorem 18.1 (Doob decomposition) Any sub-martingale \(\{X_t\}_{t \in \mathcal{T}}\) can be written in a unique way as the sum of a martingale \(\{M_t\}_{t \in \mathcal{T}}\) and an increasing process \(\{A_t\}_{t \in \mathcal{T}}\), i.e. \[
X_t = M_t + A_t
\text{.}
\]
18.3 Lag operator
The lag operator \(L\) is a function that allows us to translate a time series in time. In general, the lag operator associates \(y_t\) with its lagged value \(y_{t-1}\), i.e. \[
L(y_t) = y_{t-1}
\text{.}
\tag{18.6}\] More formally, \(L\) is the operator that takes one whole time series and produces another; the second time series is the same as the first, but moved backwards or forward one point in time. From the definition, we list some properties related to the lag operator, i.e.
Backward\(L^{k}(y_t) = y_{t-k}\).
Forward\(L^{-k}(y_t) = y_{t+k}\).
\(L(a y_t + b x_t) = a y_{t-1} + b x_{t-1}\).
18.3.1 Polynomial of Lag operator
Given a time series \(y_t\), it is possible to define polynomials of the lag operator, i.e. \[
\phi(L) y_t = y_t + \phi_1 y_{t-1} + \dots + \phi_p y_{t-p} = \sum_{i = 0}^{p} \phi_i y_{t-i}
\text{.}
\] where in general \[
\phi(L) = 1 + \phi_1 L + \phi_2 L^2 + \dots + \phi_p L^p = \sum_{j = 0}^{p} \phi_j L^j
\text{.}
\tag{18.7}\]
For the polynomial \(\phi(L)\), the following factorization holds: \[
\phi(L) = \left(1 - \frac{1}{z_1}L\right) \left(1 - \frac{1}{z_2}L\right) \dots \left(1 - \frac{1}{z_k}L\right) = \prod_{i = 1}^{k} \left(1 - \frac{1}{z_i}L\right)
\text{,}
\] where \(z_1, \dots, z_k\) are the complex solutions of the characteristic equation, i.e. \[
\phi(z) = 1 + \phi_1 z + \phi_2 z^2 + \dots + \phi_k z^k = 0
\text{.}
\] For autoregressive lag polynomials, the roots being outside the unit circle is the condition that makes the inverse lag polynomial well defined as a convergent power series, i.e. \[
|z_i| > 1 \; \forall i \iff \frac{1}{|z_i|} < 1
\text{.}
\] In other words, the modulus of the solutions must lie outside the unit circle; otherwise the geometric expansion of the inverse is not convergent. The factorization of the lag polynomial allows us to define its inverse, i.e. \[
\phi^{-1}(L) = \prod_{i = 1}^{p} \left(1 - \frac{1}{z_i} L\right)^{-1}
\text{,}
\] In fact, the inverse of a factor \((1-a_iL)\) can be expressed with a Taylor expansion as an infinite sum if and only if \(|a_i| < 1\), i.e. \[
\left(1 - a_i L\right)^{-1} = 1 + a_i L + (a_i L)^2 + \dots = \sum_{j = 0}^{\infty} a_i^j L^j \iff |a_i| < 1
\text{.}
\] that is equivalent to \(|z_i| > 1\) for all \(i\) since \(a_i = \frac{1}{z_i}\).
AR(1) and geometric series
For example, let’s consider an Autoregressive process of order 1, i.e. \[
y_t = \phi_1 y_{t-1} + e_t \iff \phi(L) y_t = e_t \iff y_t = \phi^{-1}(L) e_t
\] In fact, \[
\begin{aligned}
\phi(L) y_t & {} = y_t - \phi_1 y_{t-1} = \\
& = y_t - \phi_1 L y_{t} = \\
& = y_t (1-\phi_1 L)
\end{aligned}
\] Considering such a polynomial, its inverse polynomial \(\phi(L)^{-1}\), defined such that \(\phi(L) \phi^{-1}(L) = 1\), is defined as a geometric series, i.e. \[
\phi^{-1}(L) = 1 + \phi_1L + (\phi_1L)^2 + \dots = \sum_{j = 0}^{\infty} \phi_1^{j} L^{j} = \frac{1}{1-\phi_1 L} \iff |\phi_1| < 1
\text{,}
\] that converges if and only if \(|\phi_1| < 1\). Moreover, if \(|\phi_1| < 1\) it is possible to prove that \(\phi^{-1}(L)\) is indeed the inverse polynomial of \(\phi(L)\), in fact: \[
\begin{aligned}
\phi(L) \phi^{-1}(L) & {} = (1-\phi_1 L) \cdot \sum_{j = 0}^{\infty} (\phi_1 L)^{j} = \\
& = \sum_{j = 0}^{\infty} (\phi_1 L)^{j} - \phi_1 L\sum_{j = 0}^{\infty} (\phi_1 L)^{j} = \\
& = \sum_{j = 0}^{\infty} (\phi_1 L)^{j} - \sum_{j = 0}^{\infty} (\phi_1 L)^{j+1} = \\
& = \sum_{j = 0}^{\infty} (\phi_1 L)^{j} - \sum_{j = 0}^{\infty} (\phi_1 L)^{j} + 1 = 1
\end{aligned}
\] Therefore, the process \(y_t\) can be equivalently expressed as: \[
y_t = \phi^{-1}(L) e_t = \sum_{j = 0}^{\infty} \phi_1^{j} e_{t-j}
\] The factorization of any polynomial of the form of \(\phi(L)\) is connected to the convergence of the following geometric series, i.e. \[
\sum_{j=0}^{\infty} \phi^{j} = \frac{1}{1-\phi} \iff |\phi| < 1
\text{.}
\]
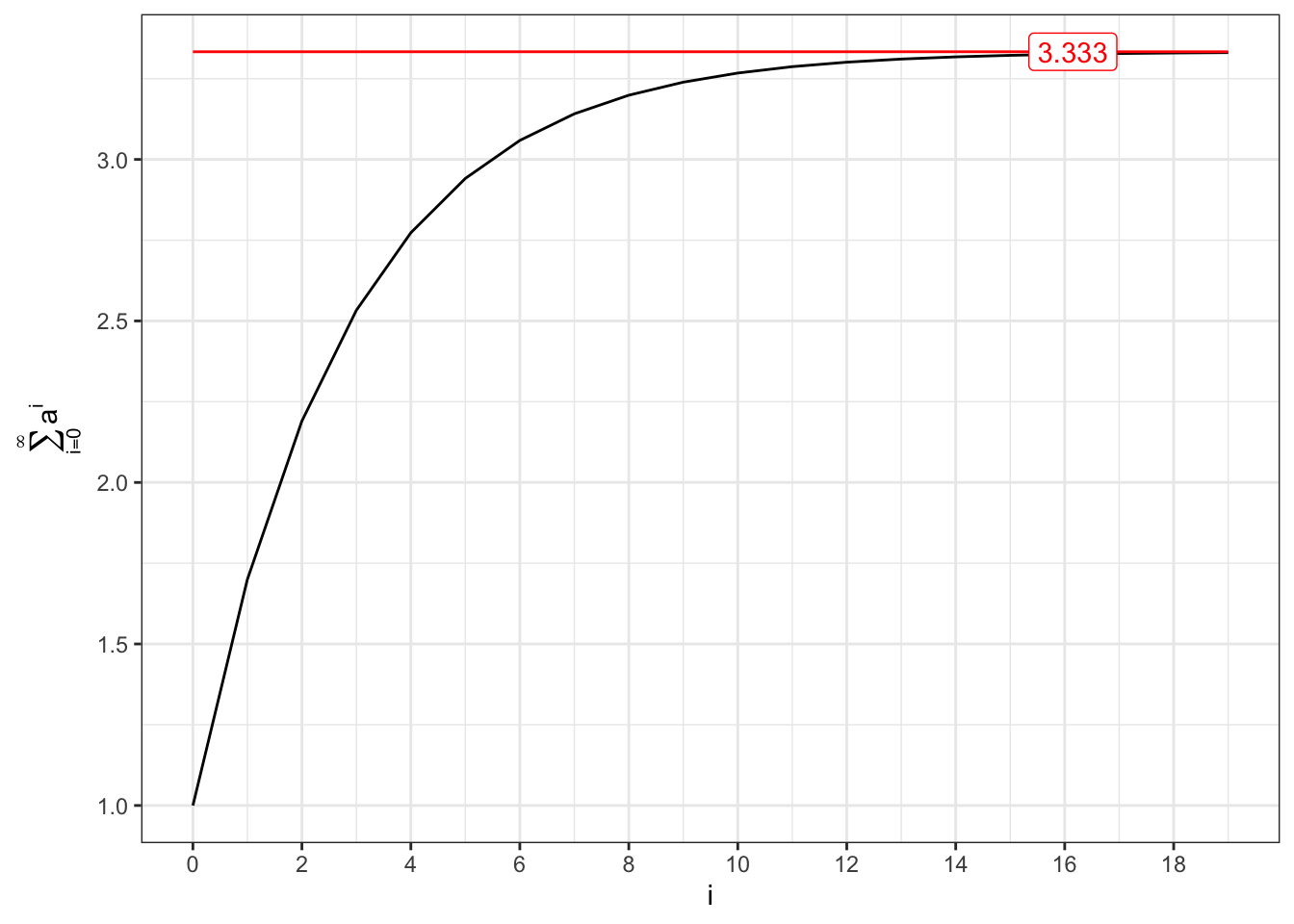
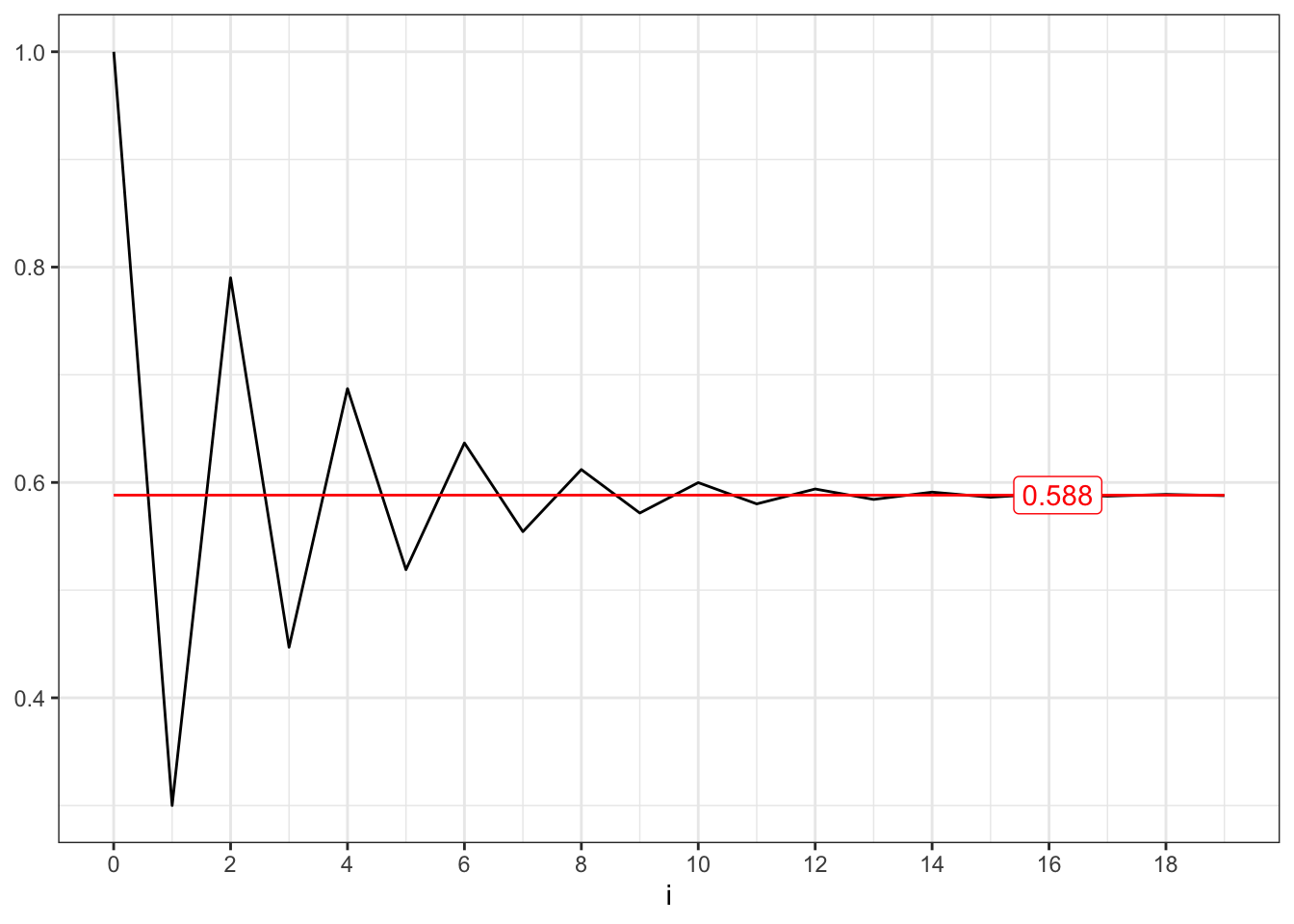
Convergent series (I)
# *************************************************# Inputs# *************************************************a <-c(0.7, -0.7)min_i <-0max_i <-20i <-seq(min_i, max_i -1, 1)y_breaks <-seq(min_i, max_i, 2)x_labels <-quantile(i, 0.85)# *************************************************# Convergent series 0 < a < 1series1 <-cumsum(a[1]^i)limit1 <-1/(1- a[1])# Convergent series -1 < a < 0series2 <-cumsum(a[2]^i)limit2 <-1/(1- a[2])
(a) \(0 < a < 1\).
(b) \(-1 < a < 0\).
Figure 18.2: Convergent series for AR(1) parameter (I).
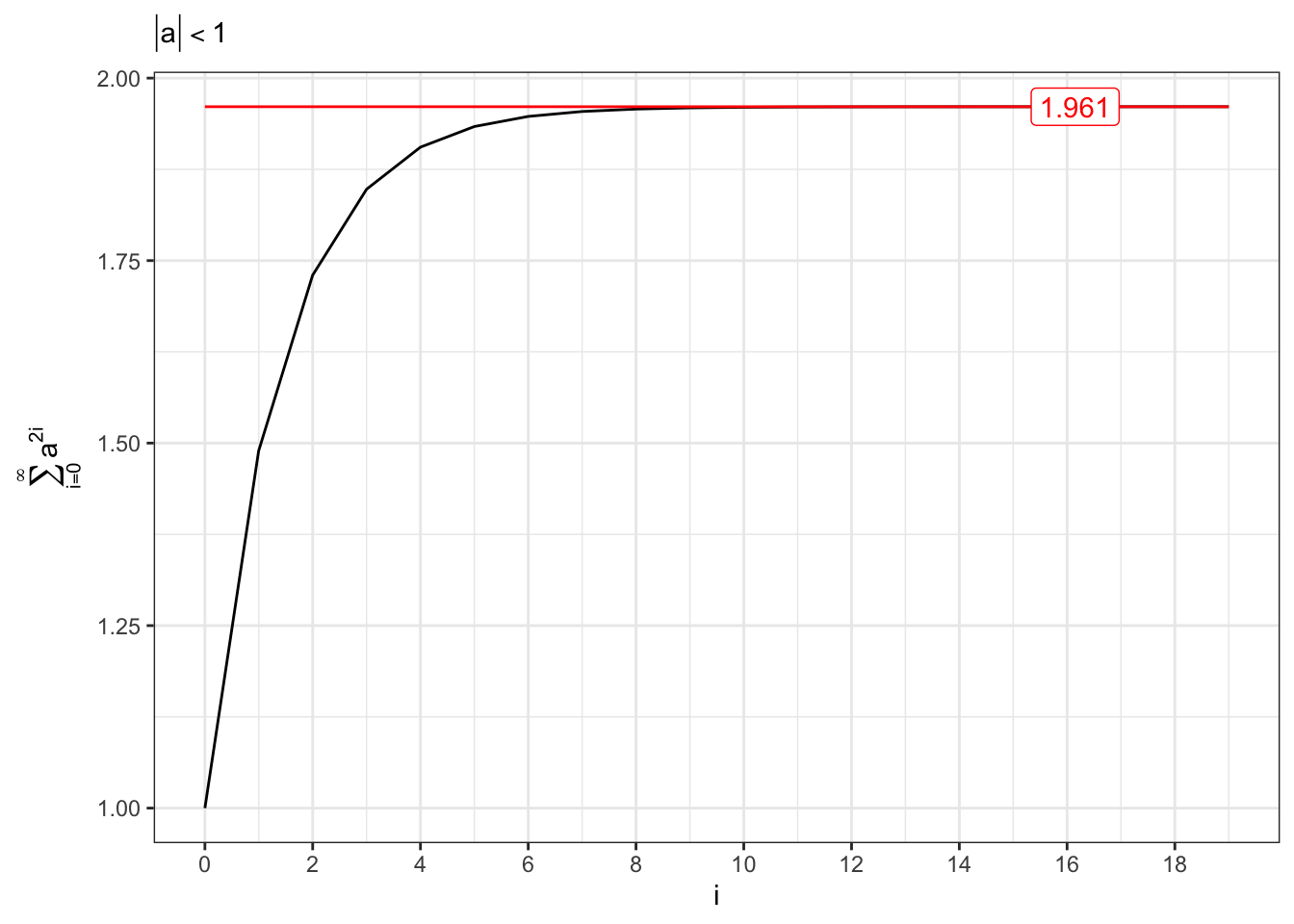
Another important series that converges if and only if \(|a|<1\), i.e. \[
\sum_{i=0}^{\infty} a^{2i} = \frac{1}{1-a^2} \iff |a| < 1
\text{.}
\] Due to the square, in this case we do not distinguish between \(0 < a < 1\) and \(-1 < a < 0\) since they lead to the same result.
Convergent series (II)
# Convergent series |a| < 1series1 <-cumsum(a[1]^(i*2))limit1 <-1/(1- a[1]^2)
Figure 18.3: Convergent series for AR(1) parameter (II).