3 Measurable maps
Reference: Chapter 3. Resnick (2005).
A measurable space is composed of a sample space \(\Omega\) and a sigma-field of subsets of \(\Omega\), namely \(\mathcal{B}\).
3.1 Maps and inverse maps
Let’s be very general and consider two measurable spaces \((\Omega, \mathcal{B})\), \((\Omega^{\prime}, \mathcal{B}^{\prime})\) and a map (function) \(X(\omega)\) that associates every \(\omega \in \Omega\) with an outcome \(\omega^{\prime} \in \Omega^{\prime}\), i.e. \[ X: (\Omega, \mathcal{B}) \to (\Omega^{\prime}, \mathcal{B}^{\prime}) \text{.} \] Then, \(X\) determines a function \(X^{-1}\) called an inverse map, i.e. \[ X^{-1}: \mathcal{P}(\Omega^{\prime}) \rightarrow \mathcal{P}(\Omega) \text{.} \] where \(\mathcal{P}\) denotes the power set, i.e. the set of all subsets and the largest sigma-field available. Then, \(X^{-1}\) is defined such that for every set \(B^{\prime}\) in \(\Omega^{\prime}\) \[ X^{-1}(B^{\prime}) = \{ \omega \in \Omega : X(\omega) \in B^{\prime}\} \text{.} \tag{3.1}\]
Exercise 3.1 Let’s consider a deck of poker cards with 52 cards in total. We have 4 groups of 13 distinct cards, where the Jack (J) is 11, the Queen (Q) is 12, the King (K) is 13 and the Ace (A) is 14. Then, let’s consider a function of the form \[ X(\omega) = \begin{cases} + 1 \quad \text{if}\; \omega \in \{2,3,4,5,6\} \\ 0 \;\;\;\quad \text{if}\; \omega \in \{7,8,9\} \\ -1 \quad \text{if}\; \omega \in \{10,11,12,13,14\} \end{cases} \] In this case the rank space has 13 distinct elements (52 cards in total), while \(\Omega^{\prime} = \{-1, 0, 1\}\) represents the possible outcomes. Suppose we observe a value \(X(\omega) = \{+1\} \subset \Omega^{\prime}\); define \(X^{-1}(\{+1\})\) according to Equation 3.1.
Solution 3.1. Suppose we observe a value \(X(\omega) = \{+1\} \subset \Omega^{\prime}\); then the inverse map \(X^{-1}\) identifies the set of \(\omega\) such that \(X(\omega) = \{+1\}\), i.e. \[ X^{-1}(\{+1\}) = \{ \omega \in \Omega : X(\omega) \in \{+1\} \} = \{2,3,4,5,6\} \text{.} \]
The inverse map \(X^{-1}\) has many properties. Among them, it preserves complementation, union and intersection.
- \(X^{-1}(\Omega^{\prime}) = \Omega\).
- \(X^{-1}(\emptyset) = \emptyset\).
- \(X^{-1}(A^{\prime \mathsf{c}}) = (X^{-1}(A^{\prime}))^{\mathsf{c}}\).
- \(X^{-1}(\Omega^{\prime} {\color{blue}{\cap}} A^{\prime}) = \Omega {\color{blue}{\cap}} X^{-1}(A^{\prime \mathsf{c}})\).
- \(X^{-1}(\bigcup_{n} A_{n}^{\prime}) = \bigcup_{n} X^{-1}(A_{n}^{\prime})\) for all \(A_{n}^{\prime} \in \mathcal{B}^{\prime}\).
Proposition 3.1 If \(\mathcal{B}^{\prime}\) is a sigma-field of subsets of \(\Omega^{\prime}\), then \(X^{-1}(\mathcal{B^{\prime}})\) is a sigma-field of subsets of \(\Omega\). Moreover, if \(\mathcal{C}^{\prime}\) is a class of subsets of \(\Omega^{\prime}\), then \[ X^{-1}(\sigma(C^{\prime})) = \sigma(X^{-1}(C^{\prime})) \text{,} \] that is, the inverse image of the sigma-field generated by the class \(\mathcal{C}^{\prime} \in \Omega^{\prime}\) is the same as the sigma-field generated in \(\Omega\) by the inverse image \(X^{-1}\). In practice, the counterimage and the generators commute. It can be difficult to know everything about the sigma-field \(\mathcal{B^{\prime}}\); however, if we know a class of subsets that generates it, namely \(\mathcal{C}^{\prime} \in \Omega^{\prime}\), we are able to recreate the sigma-field. (References: propositions 3.1.1, 3.1.2. A prob path).
3.1.1 Measurable maps
Definition 3.1 (Measurable map) Let’s consider the function \(X: (\Omega, \mathcal{B}) \to (\Omega^{\prime}, \mathcal{B}^{\prime})\), then \(X\) is \(\mathcal{B}\)-measurable, namely \(X \in \mathcal{B}/\mathcal{B}^{\prime}\), iff: \[ X \in \mathcal{B}/\mathcal{B}^{\prime} \iff X^{-1}(\mathcal{B}^{\prime}) \in \mathcal{B} \text{.} \]
Note that the measurability concept is very important since only if \(X\) is measurable is it possible to make probability statements about \(X\). In fact, probability is a type of measure, and only if \(X^{-1}(B^{\prime}) \in \mathcal{B}\) for all \(B^{\prime} \in \mathcal{B}^{\prime}\) is it possible to assign a measure (probability) to the events contained in \(\mathcal{B}\).
Definition 3.2 (Test for measurability) Consider a map \(X: (\Omega, \mathcal{B}) \rightarrow (\Omega^{\prime}, \mathcal{B}^{\prime})\) and the class \(\mathcal{C}^{\prime}\) that generates the sigma-field \(\mathcal{B}^{\prime}\), i.e. \(\mathcal{B}^{\prime} = \sigma(\mathcal{C}^{\prime})\). Then \(X\) is \(\mathcal{B}\)-measurable iff: \[ X \in \mathcal{B}/\mathcal{B}^{\prime} \iff X^{-1}(\mathcal{C}^{\prime}) \subset \mathcal{B} \text{.} \]
3.2 Random variables
Definition 3.3 (Random variable) Let’s consider a probability space \((\Omega, \mathcal{F}, \mathbb{P})\), then a random variable is a map (function) where \((\Omega^{\prime}, \mathcal{B}^{\prime}) = (\mathbb{R}, \mathcal{B}(\mathbb{R}))\). Therefore it takes values on the real line, i.e. \[ X: (\Omega, \mathcal{B}) \rightarrow (\mathbb{R}, \mathcal{B}(\mathbb{R})) \] and for every set \(B\) in the Borel sigma-field generated by the real line \(\mathcal{B}(\mathbb{R})\), the counter image of \(B\), namely \(X^{-1}(B)\) is in the sigma-field \(\mathcal{B}\) generated by \(\Omega\). Formally, \[ \forall B \in \mathcal{B}(\mathbb{R}) \quad X^{-1}(B) = \{\omega \in \Omega : X(\omega) \in B\} \subset \mathcal{B} \text{.} \] More precisely, when \(X\) is a random variable, the test for measurability (Definition 3.2) becomes: \[ X^{-1}((-\infty, y]) = [X(\omega) \le y] \subset \mathcal{B} \quad \forall y \in \mathbb{R} \text{.} \] In practice, \(B = (-\infty, y]\) that depends on the real number \(y\) while the event \([X(\omega) \le y] = X^{-1}(B)\) is exactly the counter image of \(B\).
3.2.1 sigma-field generated by a map
Let \(X: (\Omega, \mathcal{B}) \rightarrow (\Omega^{\prime}, \mathcal{B}^{\prime})\) be a measurable map, then the sigma-field generated by \(X\) is defined as: \[ \sigma(X) = X^{-1}(\mathcal{B}^{\prime}) = \{\omega \in \Omega : X(\omega) \in B^{\prime}, B^{\prime} \in \mathcal{B}^{\prime}\} \] When \(X\) is a random variable, then \((\Omega^{\prime}, \mathcal{B}^{\prime}) = (\mathbb{R}, \mathcal{B}(\mathbb{R}))\) and the sigma-field generated by \(X\) \[ \sigma(X) = X^{-1}(\mathcal{B}(\mathbb{R})) = \{\omega \in \Omega : X(\omega) \in B, B \in \mathcal{B}(\mathbb{R})\} \]
Definition 3.4 Let \(X\) be a random variable with set of possible outcomes \(\Omega^{\prime}\). Then, \(X\) is called
- discrete random variable if \(\Omega^{\prime}\) is either a finite set or a countably infinite set.
- continuous random variable if \(\Omega^{\prime}\) is an uncountable infinite set.
Definition 3.5 A random vector is a map \[ \mathbf{X}_n: (\Omega, \mathcal{B}) \rightarrow (\mathbb{R}^{n}, \mathcal{B}(\mathbb{R}^n)) \] Its counterimage \(\mathbf{X}^{-1}\) is defined as: \[ \forall B \in \mathcal{B}(\mathbb{R}^n) \quad \mathbf{X}_n^{-1}(B) = \{\omega \in \Omega : \mathbf{X}_n(\omega) \in B\} \in \mathcal{B} \] Note that, for every \(\omega\), the random vector has \(n\)-components, i.e. \[ \mathbf{X}_n(\omega) = \begin{pmatrix} X_1(\omega) \\ X_2(\omega) \\ \vdots \\ X_n(\omega) \\ \end{pmatrix} \]
Proposition 3.2 The map \(\mathbf{X}_n : (\Omega, \mathcal{B}) \rightarrow (\mathbb{R}^{n}, \mathcal{B}(\mathbb{R}^n))\) is a random vector, if and only if each component \(X_1, X_2, \dots, X_n\) is a random variable.
3.3 Induced distribution function
Consider a probability space \((\Omega, \mathcal{B}, \mathbb{P})\) and a measurable map \(X: (\Omega, \mathcal{B}) \to (\Omega^{\prime}, \mathcal{B}^{\prime})\); then the composition \(\mathbb{P} \circ X^{-1}\) is again a map. In this way, a probability measure is attached to each element \(\omega\in\Omega\). In fact, the composition is a map such that \[ \mathbb{P} \circ X^{-1}: (\Omega^{\prime}, \mathcal{B}^{\prime}) \to [0,1] \iff (\Omega^{\prime}, \mathcal{B}^{\prime}) \overset{X^{-1}}{\longrightarrow} (\Omega, \mathcal{B}) \overset{\mathbb{P}}{\longrightarrow} [0,1] \] In general, the probability of a subset \(A^{\prime} \in \mathcal{B}^{\prime}\) is denoted equivalently as: \[ \mathbb{P} \circ X^{-1}(A^{\prime}) = \mathbb{P}(X^{-1}(A^{\prime})) = \mathbb{P}(X(\omega) \in A^{\prime}) \]
Exercise 3.2 Let’s continue from Exercise 3.1 and compute the probability of \(\mathbb{P} \circ X^{-1}(\{+1\})\). Consider one random draw from the 52 cards; for each distinct number, we have 4 copies. Compute \(\mathbb{P}(X^{-1}(\{+1\}))\) and \(\mathbb{P}(X^{-1}(\{0\}))\).
Solution 3.2. The probability is computed as: \[ \begin{aligned} \mathbb{P}(X^{-1}(\{+1\})) & {} = \mathbb{P}(\{ \omega \in \Omega : X(\omega) \in \{-1\}\}) = \\ & = \mathbb{P}(\{2,3,4,5,6\}) = \\ & = \frac{5 \cdot 4}{52} = \frac{5}{13} \approx 38.46\% \end{aligned} \] Let’s consider the probability of observing either \(\{+1\}\) or \(\{-1\}\), then \[ \begin{aligned} \mathbb{P}(X^{-1}(\{-1,+1\})) & {} = \mathbb{P}(\{ \omega \in \Omega : X(\omega) \in \{-1,+1\} \}) = \\ & = \mathbb{P}(\{2,3,4,5,6, 10,11,12,13,14\}) = \\ & = \frac{10 \cdot 4}{52} = \frac{10}{13} \approx 76.92\% \end{aligned} \] Finally, by the properties of the probability measure, \(\mathbb{P}(X(\omega) \in \{0\}) = 1 - \mathbb{P}(X(\omega) \in \{-1,+1\}) \approx 23.08 \%\).
3.3.1 Distribution function on \(\mathbb{R}\)
When \(X\) is a random variable the composition \(\mathbb{P}(X^{-1}(A^{\prime}))\) is a probability measure induced on \(\mathbb{R}\) by the composition: \[ \mathbb{P}(X^{-1}((-\infty, y]) = \mathbb{P}(X \le y) = F_{X}(y) \text{,} \] for all \(y\) in \(\mathbb{R}\). Hence, the distribution function \(F_X\) of a random variable \(X\) is a function \(F_{X}: (\mathbb{R}, \mathcal{B}(\mathbb{R})) \to [0,1]\) and represents a probability measure on the real line \(\mathbb{R}\), i.e. \[ F_{X}(y) = \mathbb{P}(X(\omega) \in [-\infty, y)) = \mathbb{P}(X(\omega) \le y) \text{,} \] or for short \(\mathbb{P}(X \le y)\).
In general, the probability distribution is a function \(F_{X}: (\Omega^\prime, \mathcal{B}^{\prime}) \to [0,1]\), however when \(X\) is a random variable this means that \((\Omega^\prime, \mathcal{B}^{\prime}) = (\mathbb{R}, \mathcal{B}(\mathbb{R}))\).
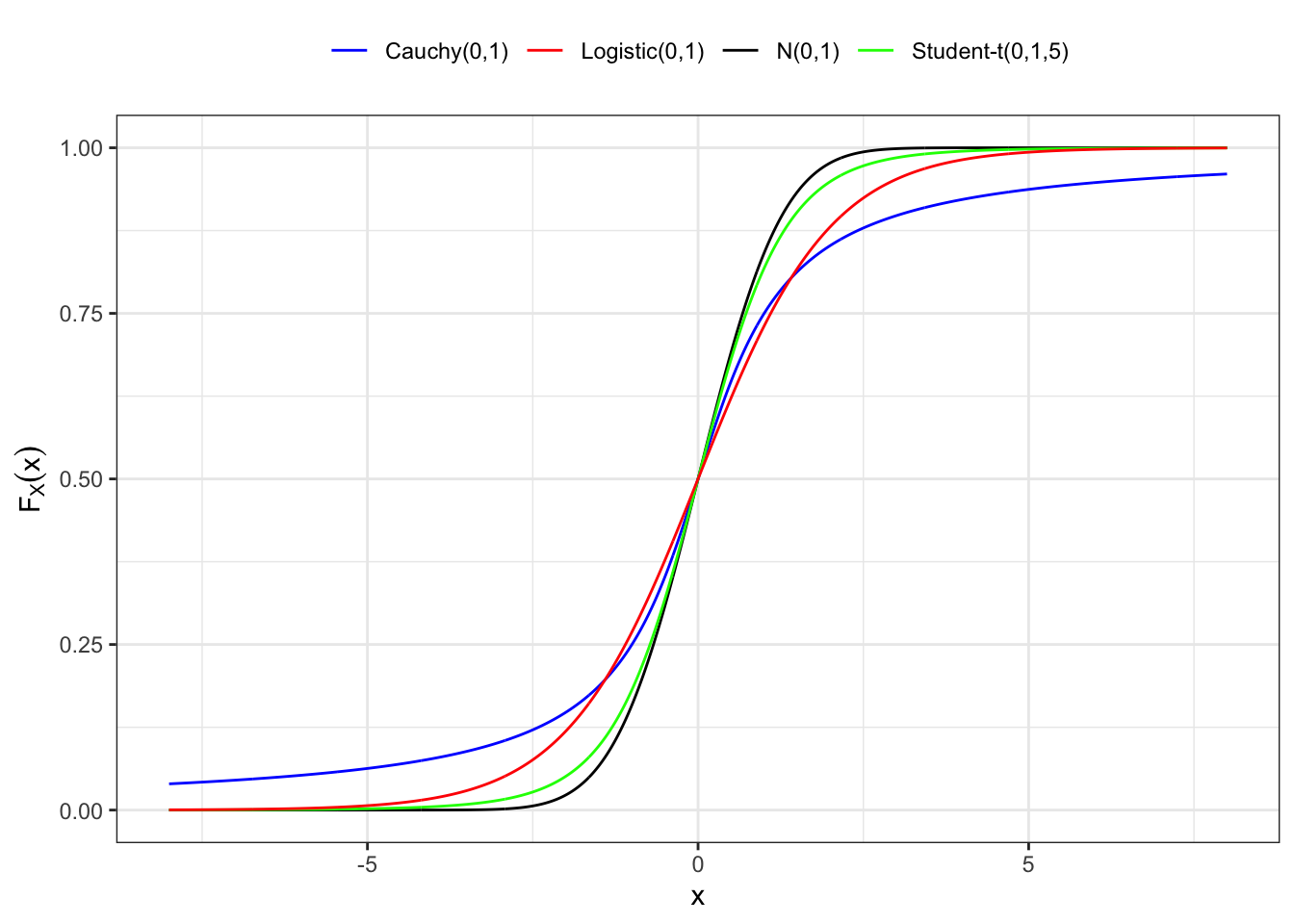
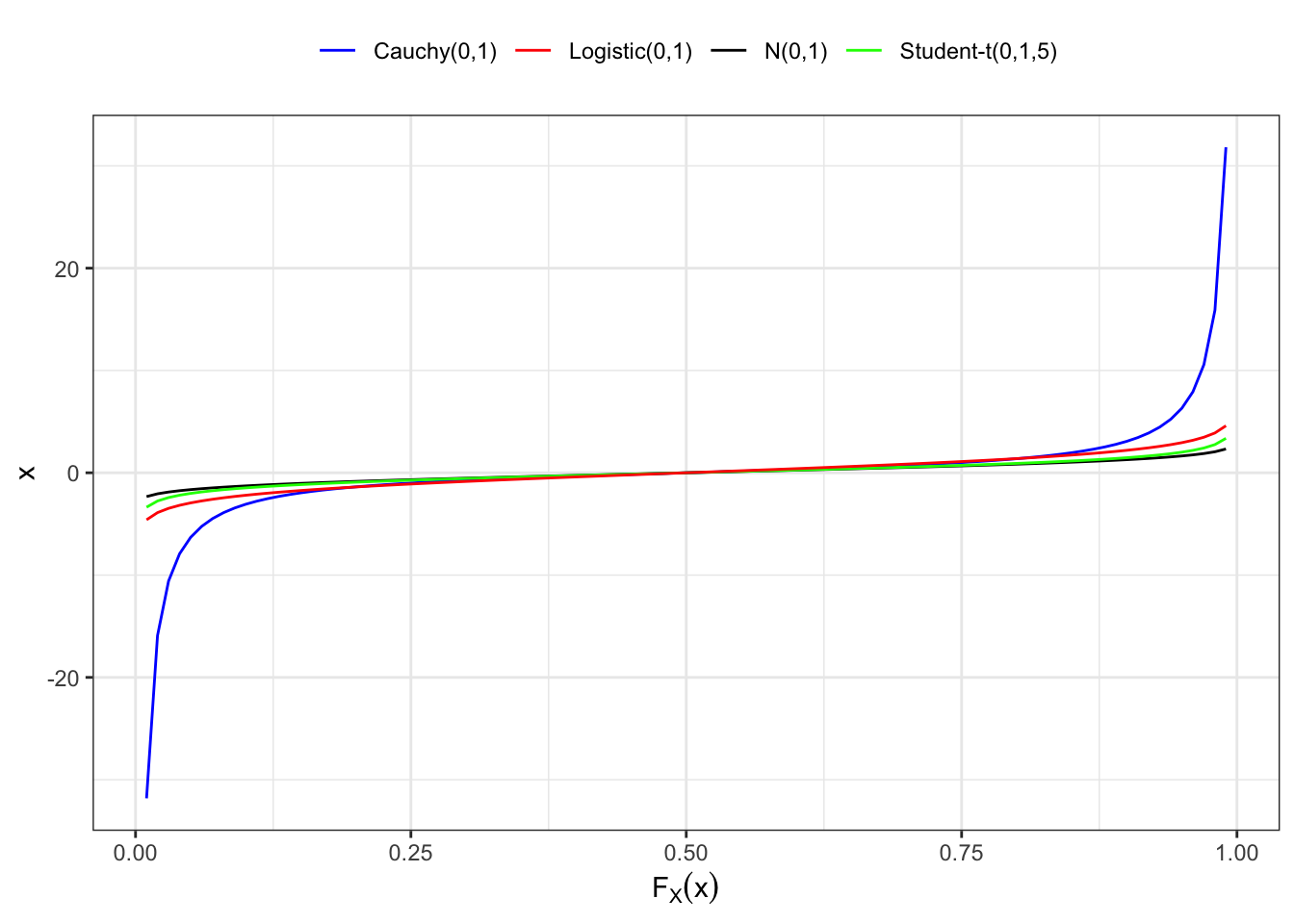
Proposition 3.3 (Density of a random variable) If a random variable \(X\) has a continuous and differentiable distribution function, then its probability density function (pdf) is defined as the first derivative of the distribution function with respect to \(y\), i.e. \[ f_{X}(y) = \frac{d}{dy}F_{X}(y) \iff dF_{X}(y) = f_X(y) dy \text{.} \tag{3.2}\] Instead, for a discrete random variable, we call it the probability mass function (pmf), i.e. \[ f_{X}(y) = \mathbb{P}(X = y) \text{.} \] Considering a generic domain \(\mathcal{D} \subseteq \mathbb{R}\) for the random variable \(X\), then the function \(f_X\) satisfies two fundamental properties, i.e.
- Positivity: \(f_X(y) \ge 0\) for all \(y \in \mathcal{D}\).
- Normalization: \(\int_{\mathcal{D}} f_X(y) dy = 1\) or \(\sum_{y \in \mathcal{D}} \mathbb{P}(X = y) = 1\).
In general, any function \(f_X\) that satisfies properties 1. and 2. in Proposition 3.3 is the density function of some (unknown) random variable.
3.3.2 Survival function
For any random variable with distribution \(F_X\), the survival distribution is defined as: \[ \bar{F}_X(y) = \mathbb{P}(X \ge y) = 1 - F_X(y) \text{.} \]
Definition 3.6 (Criterion I for heavy tails) A distribution function \(F_X\) is said to be:
Light tailed if for some \(\lambda > 0\) \[ \lim_{y\to\infty}\frac{\bar{F}_X(y)}{e^{-\lambda y}} = \begin{cases} 0 & \text{faster than exponential} \\ 0 < l < \infty & \text{same speed as the exponential} \end{cases} \]
Heavy tailed if for all \(\lambda > 0\) \[ \lim_{y\to\infty}\frac{\bar{F}_X(y)}{e^{-\lambda y}} = \infty \quad \text{slower than the exponential} \text{.} \]