9 Introduction
9.1 Population and Sample
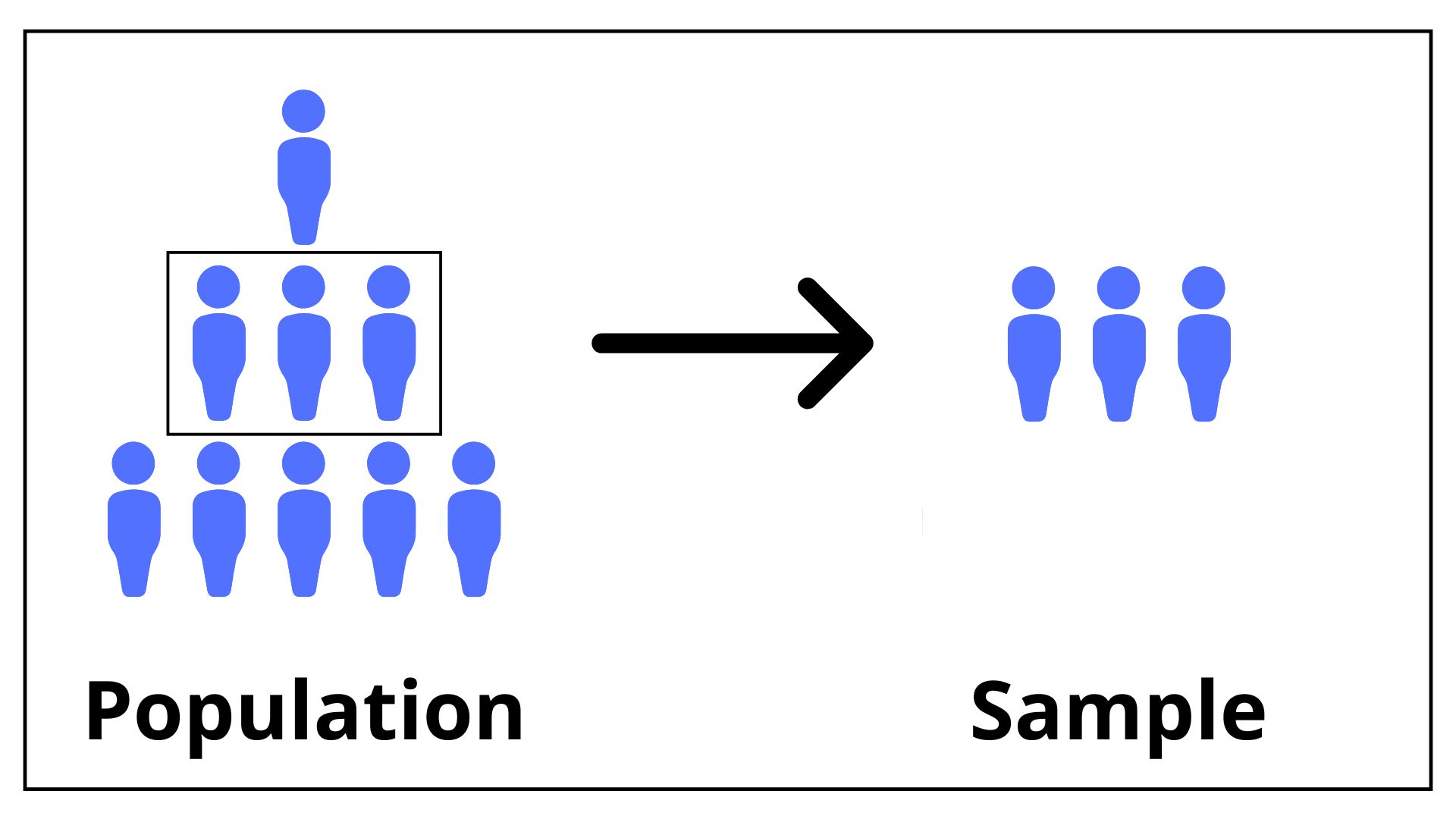
A population refers to the entire group of individuals or instances about whom we hope to learn. It encompasses all possible subjects or observations that meet a set of criteria. The population is the complete set of items that interest the researcher, and it can be finite (e.g. the students in a particular school) or infinite (e.g. the number of times a die can be rolled). A population size is given by the number of distinct elements and it includes every individual or observation of interest.
A sample is a subset of the population that is used to represent the population. Since studying an entire population is often impractical due to constraints like time, cost, and accessibility, samples provide a manageable and efficient way to gather data and make inferences about the population. It is important that the sample is representative of the population of interest to allow for valid inferences. It is always important to distinguish between a random sample, e.g. a random group of students in 5th year from a school to make inference about the students at the 5th year of such school, and a convenience sample, e.g. a class of 5th year students who are easily accessible to the researcher, but that can be not representative of all the 5th year students in the school.
| Aspect | Population | Sample |
|---|---|---|
| Definition | Entire group of interest | Subset of the population |
| Size | Large, potentially infinite | Small, manageable |
| Data Collection | Often impractical to study directly | Practical and feasible |
| Purpose | To understand the whole group | To make inferences about the population |
9.2 Estimators
Let’s consider a statistical model depending on some unknown parameter
Since the estimator is a random variable itself, one can define some metrics to compare different estimators of the same parameter. Firstly, let’s consider the bias, the distance between the average of the collection of estimates and the single parameter being estimated, i.e.
- Biased, when
- Unbiased, when
The variance is used to indicate how far the collection of estimates are from the expected value of the estimates, i.e.
9.2.1 Properties
As for some desirable property of an estimator one have
Consistency (weak): Definition 8.3
Efficiency: Among unbiased estimators, one with minimal variance is called (finite-sample) efficient; asymptotically efficient means it attains the Cramér–Rao lower bound (CRLB) limit.
Asymptotic normality: for some normalizing sequence
9.2.2 Sufficiency and Completeness
Theorem 9.1 A statistic
Theorem 9.2 Rao–Blackwell. If
A statistic
:::{#thm-lehmann–scheffe .thm} Lehmann–Scheffé. If
9.2.3 Methods of construction
Method of Moments (MoM): Solve sample moments
Maximum Likelihood (MLE): Maximize
Rao–Blackwellization: Improve any unbiased estimator by conditioning on a sufficient statistic; with completeness, obtain UMVU (Lehmann–Scheffé).